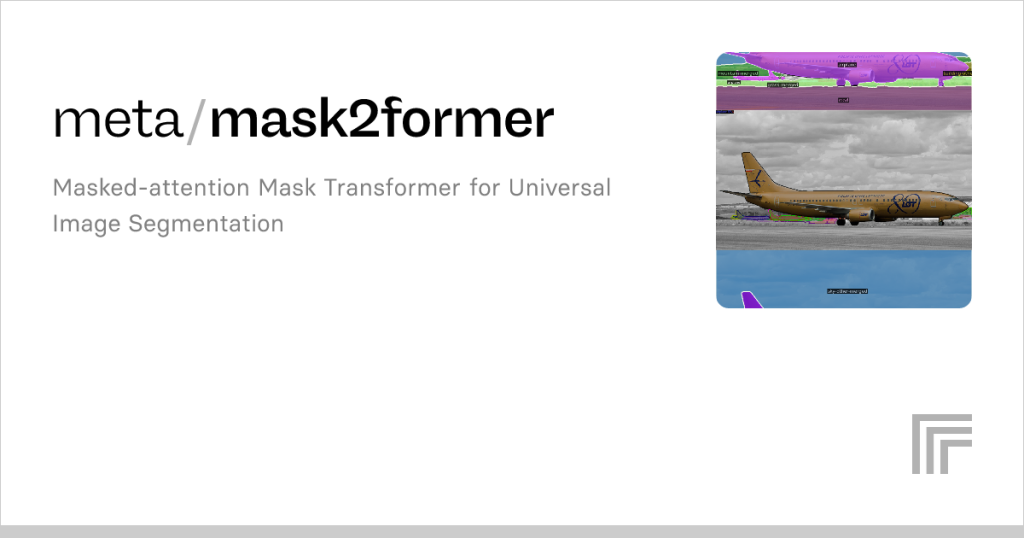

Mask2Former stands as a transformative milestone in artificial intelligence, particularly within the realm of computer vision. This advanced transformer-based model is engineered to tackle universal image segmentation, seamlessly addressing semantic, instance, and panoptic segmentation within a single, cohesive framework. By overcoming the constraints of earlier segmentation models, Mask2Former delivers unparalleled performance, establishing itself as a cornerstone for analyzing intricate visual scenes. Its ability to unify diverse segmentation tasks has ignited widespread enthusiasm among AI researchers, developers, and industry professionals seeking robust solutions.
The architecture of Mask2Former capitalizes on the revolutionary capabilities of transformer models, which first reshaped natural language processing and are now redefining computer vision applications. By introducing a unified approach, it eliminates the necessity for task-specific architectures, thereby streamlining development processes and minimizing computational demands. Central to its design is the innovative masked attention mechanism, which enhances efficiency by focusing processing on relevant image regions, producing highly accurate segmentation masks for applications ranging from autonomous navigation to medical diagnostics.
Delving into Mask2Former’s significance involves examining its technical underpinnings, operational strengths, and far-reaching implications. Its capacity to generalize across multiple segmentation tasks positions it as a pivotal tool for building sophisticated AI systems capable of interpreting complex visual environments. This comprehensive article explores Mask2Former’s architecture, key features, diverse applications, and its profound influence on the AI landscape, offering valuable insights for researchers, practitioners, and enthusiasts eager to understand its role in shaping the future of computer vision.
Understanding Image Segmentation in AI
Defining Image Segmentation
Image segmentation is a fundamental process in computer vision that involves partitioning an image into distinct, meaningful regions or segments, each corresponding to specific objects or areas. This technique enables machines to interpret visual data with human-like precision, identifying boundaries and categorizing pixels based on their properties. Segmentation is essential for tasks like object recognition, scene analysis, and spatial reasoning, forming the backbone of advanced AI-driven visual systems across various domains.
Exploring Types of Image Segmentation
Image segmentation encompasses three primary types: semantic, instance, and panoptic, each serving unique purposes. Semantic segmentation assigns a class label to every pixel, grouping similar objects, such as identifying all trees in a forest image. Instance segmentation goes further by distinguishing individual objects within the same class, providing unique masks for each, like separating each tree. Panoptic segmentation merges both approaches, delivering a comprehensive scene understanding by labeling all pixels and identifying distinct object instances.
Importance of Segmentation in AI Systems
Segmentation is critical for enabling AI to emulate human visual perception, underpinning applications that require detailed scene comprehension. In autonomous vehicles, it facilitates the identification of pedestrians, vehicles, and road signs, ensuring safe navigation. In medical imaging, segmentation aids in detecting abnormalities, such as tumors in MRI scans, enhancing diagnostic accuracy. By providing granular insights into visual data, segmentation empowers AI to interact intelligently with complex environments, driving advancements in both research and real-world applications.
The Evolution of Segmentation Models
Early Approaches to Segmentation
The journey of image segmentation began with traditional methods relying on hand-crafted features, such as edge detection, thresholding, or clustering algorithms. These early techniques struggled with complex, real-world scenes due to their limited adaptability and reliance on manual tuning. The introduction of deep learning brought convolutional neural networks (CNNs), with models like Fully Convolutional Networks (FCN) marking a significant leap forward. However, these early deep learning models were constrained by task-specific designs and high computational costs.
Emergence of Transformer-Based Models
The rise of transformers, initially transformative in natural language processing, catalyzed a paradigm shift in computer vision. Models like DETR (DEtection TRansformer) demonstrated the power of attention mechanisms in capturing long-range dependencies within images, surpassing the limitations of CNNs. This breakthrough inspired the development of transformer-based segmentation models, which offered enhanced context awareness and accuracy. By leveraging global image relationships, transformers paved the way for more flexible and powerful segmentation frameworks, setting the stage for innovations like Mask2Former.
Challenges of Pre-Mask2Former Models
Before Mask2Former, segmentation models faced significant hurdles, including the need for separate architectures tailored to semantic, instance, or panoptic tasks, which increased complexity and inefficiency. These models often struggled with scalability, generalization across diverse datasets, and handling high-resolution images. Training instability and computational overhead further limited their practical utility, particularly for large-scale or real-time applications. These challenges underscored the demand for a unified, robust, and efficient segmentation framework, which Mask2Former was designed to address.
Mask2Former’s Architecture Explained
Core Components of the Architecture
Mask2Former’s architecture is a sophisticated blend of a transformer-based backbone, a pixel decoder, and a transformer decoder, working in harmony to achieve superior segmentation. The backbone extracts rich, multi-scale feature representations from input images, capturing both local and global contexts. The pixel decoder refines these features to produce high-resolution outputs, while the transformer decoder generates a fixed set of queries that translate into precise segmentation masks, enabling seamless handling of multiple segmentation tasks.
Masked Attention Mechanism
- Optimized Computation: Masked attention focuses processing on specific image regions, reducing computational complexity significantly.
- Contextual Precision: Enhances segmentation accuracy by prioritizing relevant visual features and relationships.
- Scalable Design: Supports efficient processing of high-resolution images without excessive memory usage.
- Task Versatility: Adapts dynamically to semantic, instance, and panoptic segmentation requirements.
- Enhanced Stability: Improves training and inference robustness across diverse datasets and conditions.
Unified Segmentation Framework
Mask2Former redefines segmentation by treating all tasks as mask classification problems, generating a fixed number of mask predictions, each paired with a class label or instance ID. This unified approach eliminates the need for task-specific heads, simplifying both training and inference processes. By leveraging shared components and a streamlined workflow, Mask2Former achieves consistent, high-quality performance across semantic, instance, and panoptic segmentation, making it a highly versatile and efficient solution.
Key Features of Mask2Former
Universal Segmentation Capabilities
- Multi-Task Integration: Seamlessly handles semantic, instance, and panoptic segmentation within one model.
- High Accuracy: Delivers state-of-the-art results across all segmentation types consistently.
- Workflow Efficiency: Reduces complexity by eliminating the need for multiple specialized models.
- Broad Applicability: Excels on diverse datasets, from urban scenes to medical imagery.
- Developer-Friendly: Simplifies implementation for researchers and industry practitioners alike.
Superior Efficiency and Scalability
Mask2Former optimizes resource utilization through its masked attention mechanism and modular architecture, enabling efficient processing of high-resolution images. This efficiency makes it suitable for real-time applications, such as autonomous driving or live video analysis. Its scalability allows it to perform effectively across datasets of varying sizes and complexities, from small-scale academic experiments to large-scale industrial deployments, ensuring broad applicability and robust performance.
Robustness Across Diverse Datasets
The model’s transformer-based design enables it to generalize effectively across varied datasets, such as COCO, Cityscapes, ADE20K, and medical imaging benchmarks. Mask2Former excels in challenging scenarios, including cluttered scenes, low-light conditions, or images with fine details, delivering reliable segmentation results. This robustness positions it as a go-to solution for applications requiring consistent performance in diverse, real-world environments, from urban planning to satellite image analysis.
Applications of Mask2Former in AI
Autonomous Driving and Robotics
- Obstacle Identification: Detects pedestrians, vehicles, road signs, and other obstacles with precision.
- Comprehensive Scene Analysis: Provides detailed segmentation for navigating complex urban environments.
- Real-Time Performance: Supports fast inference for dynamic, time-sensitive decision-making.
- Path Optimization: Enables robots to map and navigate spaces with high accuracy.
- Safety Assurance: Enhances reliability in unpredictable, real-world driving or robotic scenarios.
Medical Imaging and Diagnostics
Mask2Former’s precision and versatility make it an invaluable tool in medical imaging, where it excels at tasks like tumor detection, organ segmentation, and anomaly identification. It accurately delineates structures in MRI, CT, and X-ray scans, supporting clinicians in diagnosis and treatment planning. Its ability to generalize across imaging modalities ensures consistent performance, driving advancements in automated diagnostics, personalized medicine, and medical research.
Augmented Reality and Interactive Gaming
In augmented reality, Mask2Former facilitates seamless integration of virtual elements into real-world scenes by providing accurate environmental segmentation. In gaming, it enhances scene rendering, object interaction, and character animation, creating immersive and responsive experiences. Its computational efficiency ensures smooth performance on resource-constrained devices like mobile phones or AR headsets, making it a critical tool for developers building cutting-edge, visually rich applications.
Impact and Future Potential of Mask2Former
Driving Advances in Computer Vision Research
Mask2Former has redefined benchmarks in image segmentation, inspiring researchers to explore unified models for other vision tasks. Its open-source availability fosters global collaboration, enabling the AI community to extend its capabilities and integrate it into novel frameworks. By addressing the shortcomings of previous models, Mask2Former catalyzes innovations in transformer-based architectures, potentially influencing areas like object detection, image synthesis, and video processing.
Industry Adoption and Practical Impact
Industries such as automotive, healthcare, entertainment, and urban planning are increasingly adopting Mask2Former for its versatility, efficiency, and high performance. Its ability to streamline development workflows and reduce computational costs makes it a cost-effective solution for commercial applications. As AI adoption accelerates, Mask2Former’s scalability and robustness position it as a key enabler for real-world solutions, from smart city infrastructure to advanced medical imaging systems.
Future Directions and Enhancements
The success of Mask2Former opens avenues for further advancements, such as integrating temporal data for video segmentation or optimizing energy efficiency for edge devices like IoT sensors. Researchers are exploring its potential in generative AI, enabling applications like scene reconstruction or creative content generation. As datasets expand and new challenges emerge, Mask2Former’s flexible framework will likely evolve, ensuring its continued relevance in the dynamic field of computer vision.
Conclusion
Mask2Former represents a monumental leap in AI-driven image segmentation, delivering a unified, efficient, and robust solution for semantic, instance, and panoptic tasks. Its transformer-based architecture, innovative masked attention mechanism, and applicability across domains like autonomous driving, medical imaging, and augmented reality underscore its transformative impact. By simplifying workflows, enhancing performance, and fostering innovation, Mask2Former empowers researchers and industries to redefine how AI interprets complex visual worlds, paving the way for a future of intelligent, vision-driven solutions.