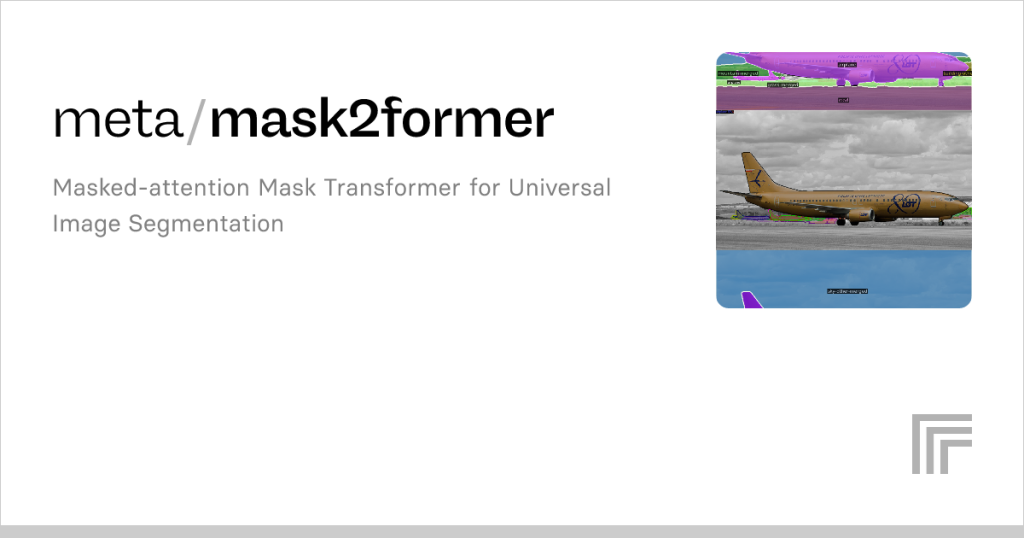

The world of computer vision has been transformed by advancements in deep learning, with models like Mask2Former pushing boundaries in tasks such as image segmentation. As researchers and developers explore these cutting-edge models, a common question arises: does Mask2Former leverage the power of transformers, the architecture that revolutionized natural language processing and made significant inroads into vision tasks? Understanding the role of transformers in Mask2Former offers insight into its capabilities and performance.
Transformers, introduced in the seminal paper “Attention is All You Need,” rely on self-attention mechanisms to process data, enabling models to weigh the importance of different elements in a sequence or image. Their success in language tasks has spurred their adoption in computer vision, with models like Vision Transformers (ViT) showcasing their potential. Mask2Former, a state-of-the-art model for image segmentation, prompts curiosity about whether it harnesses this architecture to achieve its impressive results.
To answer whether Mask2Former uses transformers, it’s essential to dive into its architecture, explore its components, and compare it to other segmentation models. This article breaks down Mask2Former’s design, its reliance on transformer-based mechanisms, and how it fits into the broader landscape of computer vision. By examining its building blocks and innovations, readers can grasp the model’s strengths and its place in modern AI research.
Understanding Mask2Former’s Architecture
Core Components of Mask2Former
Mask2Former is a universal image segmentation model designed to handle tasks like instance, semantic, and panoptic segmentation. Its architecture builds on the success of its predecessor, MaskFormer, but introduces enhancements for efficiency and performance. The model processes images through a backbone and a pixel decoder, followed by a transformer-based module. This structure allows it to generate high-quality segmentation masks. The transformer component is central to its ability to model relationships across image regions.
Role of the Pixel Decoder
The pixel decoder in Mask2Former refines features extracted from the backbone, typically a convolutional neural network (CNN) or a vision transformer. It produces per-pixel embeddings that capture detailed spatial information. These embeddings are critical for generating accurate segmentation masks. The decoder leverages multi-scale features to ensure robustness across different object sizes. Its output feeds into the transformer module, bridging the gap between feature extraction and mask prediction.
Transformer Module Integration
The transformer module in Mask2Former is where the model’s innovation shines. It takes the pixel decoder’s output and applies self-attention and cross-attention mechanisms to model global relationships between image regions. This module generates a set of queries that predict object masks and their corresponding classes. By incorporating transformers, Mask2Former captures long-range dependencies, making it highly effective for complex segmentation tasks. This confirms that transformers are indeed a core part of its architecture.
How Transformers Power Mask2Former
Self-Attention in Mask2Former
Transformers rely on self-attention to weigh the importance of different parts of the input data. In Mask2Former, self-attention enables the model to focus on relevant image regions when generating masks. This mechanism allows the model to understand contextual relationships, such as distinguishing objects from backgrounds. Self-attention enhances the model’s ability to handle cluttered or overlapping objects. It’s a key factor in Mask2Former’s superior performance.
Benefits of Transformer-Based Design
The transformer-based design in Mask2Former offers several advantages:
- Global Context Understanding: Captures relationships across the entire image, improving segmentation accuracy.
- Flexibility Across Tasks: Handles instance, semantic, and panoptic segmentation with a unified approach.
- Robustness to Variations: Adapts to different object scales and complex scenes.
- Efficient Query-Based Prediction: Uses a fixed number of queries to predict masks, reducing computational overhead.
- Improved Generalization: Performs well on diverse datasets due to its attention-driven architecture.
Comparison with CNN-Based Models
Unlike traditional CNN-based segmentation models, Mask2Former’s transformer module allows it to model long-range dependencies more effectively. CNNs rely on local receptive fields, which can struggle with global context. Transformers overcome this limitation by processing the entire image simultaneously. This makes Mask2Former more adept at handling complex scenes. However, it may require more computational resources than lightweight CNN models.
Mask2Former vs. MaskFormer: Transformer Evolution
Improvements Over MaskFormer
Mask2Former builds on MaskFormer by refining its transformer-based approach. While MaskFormer introduced a query-based transformer framework for segmentation, Mask2Former enhances efficiency and accuracy. It uses fewer queries and optimizes the transformer module for faster inference. These improvements make Mask2Former more practical for real-world applications. The transformer architecture remains central to both models.
Query-Based Transformer Mechanism
Both MaskFormer and Mask2Former use a query-based transformer mechanism, where a fixed number of learnable queries predict object masks. In Mask2Former, the queries are more efficient, reducing redundancy and improving mask quality. The transformer processes these queries through attention layers to align them with image features. This mechanism ensures precise segmentation across diverse tasks. The evolution in query handling highlights Mask2Former’s advancements.
Performance Gains from Transformers
Mask2Former’s transformer module contributes to significant performance gains over MaskFormer. It achieves higher accuracy on benchmarks like COCO and ADE20K, particularly in panoptic segmentation. The transformer’s ability to model global interactions allows Mask2Former to excel in challenging scenarios, such as scenes with multiple overlapping objects. These gains underscore the importance of transformers. The model’s success is tied to its attention-driven design.
Key Features of Mask2Former’s Transformer Module
Cross-Attention for Mask Prediction
The transformer module in Mask2Former uses cross-attention to align learnable queries with pixel embeddings from the decoder. This process ensures that each query focuses on a specific object or region in the image. Cross-attention enables precise mask prediction by correlating queries with relevant image features. It’s a critical component for generating accurate segmentation masks. This mechanism leverages the transformer’s strength in modeling relationships.
- Query-Feature Alignment: Matches queries to specific image regions for accurate mask generation.
- Dynamic Focus: Adjusts attention based on object characteristics, improving robustness.
- Reduced Noise: Filters irrelevant information, enhancing mask clarity.
- Scalable Design: Handles varying numbers of objects efficiently.
- Context-Aware Prediction: Incorporates global image context for better segmentation.
Multi-Scale Feature Integration
Mask2Former’s transformer module integrates multi-scale features from the pixel decoder, allowing it to handle objects of different sizes. This is achieved through attention mechanisms that process features at various resolutions. The transformer ensures that both fine-grained details and global context are considered during mask prediction. This capability enhances the model’s versatility. It performs well across diverse segmentation tasks.
Efficient Query Optimization
The transformer module optimizes the number of queries used for mask prediction, making Mask2Former computationally efficient. Unlike MaskFormer, which used a larger number of queries, Mask2Former reduces redundancy while maintaining accuracy. The transformer’s attention layers refine query interactions with image features. This optimization speeds up inference without sacrificing performance. It’s a key advancement in Mask2Former’s design.
Applications of Mask2Former’s Transformer Architecture
Real-World Use Cases
Mask2Former’s transformer-based architecture enables a range of applications:
- Autonomous Driving: Segments objects like pedestrians, vehicles, and road signs in real-time.
- Medical Imaging: Identifies structures in MRI or CT scans with high precision.
- Robotics: Enables robots to understand and navigate complex environments.
- Augmented Reality: Supports accurate object overlay in AR applications.
- Video Analysis: Tracks and segments objects across video frames for surveillance or editing.
Advantages in Complex Scenes
The transformer architecture excels in scenes with overlapping objects or cluttered backgrounds. Its ability to model global relationships ensures accurate segmentation in challenging conditions. For example, in crowded urban environments, Mask2Former can distinguish between closely spaced objects. This makes it ideal for real-world applications requiring robust performance. The transformer’s flexibility is a key strength.
Scalability Across Datasets
Mask2Former’s transformer module allows it to generalize across diverse datasets, such as COCO, Cityscapes, and ADE20K. The attention mechanisms adapt to different data distributions, ensuring consistent performance. This scalability is crucial for deploying the model in varied scenarios. The transformer’s design supports transfer learning effectively. It’s a versatile tool for computer vision research.
Challenges and Limitations of Transformers in Mask2Former
Computational Complexity
While transformers enhance Mask2Former’s performance, they increase computational demands compared to CNN-based models. The attention mechanisms require significant memory and processing power, especially for high-resolution images. This can limit deployment on resource-constrained devices. Researchers are exploring ways to optimize transformer efficiency. Balancing performance and resource usage remains a challenge.
Training Data Requirements
Transformers in Mask2Former rely on large, annotated datasets to achieve optimal performance. Training on smaller datasets may lead to overfitting or reduced generalization. High-quality annotations for segmentation tasks are costly and time-consuming to produce. This dependency can hinder scalability in niche applications. Data augmentation strategies are often needed to mitigate this issue.
Interpretability of Attention Mechanisms
The attention mechanisms in Mask2Former’s transformer module are powerful but complex, making them harder to interpret than traditional CNNs. Understanding why the model focuses on specific regions can be challenging. This lack of interpretability may pose issues in critical applications like medical imaging. Researchers are working on techniques to visualize attention patterns. Improving interpretability is an ongoing area of study.
Conclusion
Mask2Former indeed uses transformers, leveraging their self-attention and cross-attention mechanisms to excel in image segmentation tasks. Its transformer module, integrated with a pixel decoder and backbone, enables robust performance across instance, semantic, and panoptic segmentation. By capturing global context and optimizing query-based predictions, Mask2Former outperforms its predecessors and traditional CNN models. Despite challenges like computational complexity, its transformer-driven design makes it a powerful tool for computer vision, driving advancements in autonomous systems, medical imaging, and beyond.