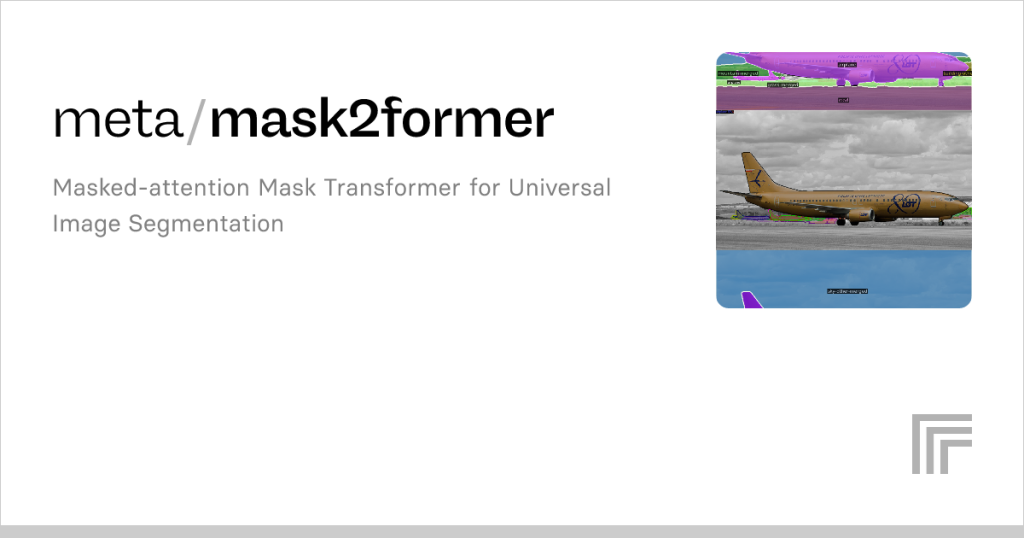

In computer vision research, segmentation has always remained a key challenge due to the complexity of visual scenes and the diversity of real-world applications. Traditional segmentation models often struggled with task-specific limitations, requiring separate architectures for semantic segmentation, instance segmentation, or panoptic segmentation. However, the introduction of Mask2Former has significantly shifted how segmentation tasks are approached, offering one universal framework.
Mask2Former, developed by researchers from Facebook AI Research, stands as a strong successor to MaskFormer. Unlike conventional models that depend on rigid pipelines, Mask2Former leverages a transformer-based architecture and masked attention mechanism to unify multiple segmentation tasks into one generalized model. The result is a system that is more flexible, efficient, and adaptable across domains ranging from autonomous driving to healthcare imaging.
This innovation has not only improved segmentation accuracy but also reduced the complexity of training separate models for different purposes. By employing a query-based design and applying mask attention across varying resolutions, Mask2Former simplifies integration into industrial and academic environments. This article explores what tasks Mask2Former supports, breaking them down systematically with structured explanations, examples, and SEO-focused clarity.
Semantic Segmentation with Mask2Former
Understanding Semantic Segmentation
Semantic segmentation assigns class labels to every pixel of an image. Unlike object detection that relies on bounding boxes, semantic segmentation provides precise pixel-level understanding. Mask2Former redefines this task by leveraging transformer-based queries and producing masks directly, removing post-processing dependencies.
Advantages Over Traditional Methods
By applying multi-scale masked attention, Mask2Former effectively captures both fine-grained details and global context. This makes it robust against challenges like low-light scenes, complex textures, or overlapping objects. As a result, industries that require highly detailed labeling, such as satellite mapping or medical imaging, benefit significantly.
Applications of Semantic Segmentation
Semantic segmentation using Mask2Former has practical applications in:
- Urban planning through accurate land cover mapping
- Agriculture monitoring by analyzing crop health
- Healthcare imaging for segmenting tissues and organs
- AR/VR for background replacement and environment mapping
Instance Segmentation with Mask2Former
What is Instance Segmentation
Instance segmentation goes beyond classifying pixels by differentiating between individual objects of the same type. For example, separating five people in a crowd rather than labeling them all as “person.”
Mask2Former’s Unique Approach
Instead of relying on bounding-box anchors, Mask2Former uses query-based mask predictions. Each query corresponds to a potential object, ensuring more accurate boundaries even in cluttered scenes. This reduces confusion in overlapping scenarios, making results more reliable.
Real-World Benefits of Instance Segmentation
- Retail and e-commerce for precise product detection
- Manufacturing for quality inspection on assembly lines
- Security and surveillance for real-time person tracking
Panoptic Segmentation with Mask2Former
What is Panoptic Segmentation
Panoptic segmentation unifies semantic and instance segmentation. It labels both “stuff” (sky, road, grass) and “things” (cars, humans, animals) in one holistic output.
How Mask2Former Handles Panoptic Segmentation
Mask2Former applies multi-scale masked attention to manage stuff and things simultaneously. By integrating global and local features, it avoids conflicts such as overlapping labels or missing boundaries, resulting in smooth, unified outputs.
Applications of Panoptic Segmentation
Panoptic segmentation using Mask2Former is used in:
- Self-driving cars for full-scene understanding
- Robotics for object manipulation and environment awareness
- Smart cities for monitoring infrastructure and pedestrian flow
Video Instance Segmentation with Mask2Former
Concept of Video Instance Segmentation
Video instance segmentation involves tracking and segmenting objects across video frames. It requires temporal consistency, identity preservation, and adaptability to motion or occlusion.
Mask2Former’s Contribution
Mask2Former extends its query-based system into videos by applying temporal attention. This ensures consistent object IDs across frames, reducing common errors like identity switches or lost tracking.
Use Cases of Video Instance Segmentation
- Sports analytics for player movement tracking
- Traffic monitoring for counting and categorizing vehicles
- Wildlife research for observing animals in natural habitats
Video Panoptic Segmentation with Mask2Former
Concept of Video Panoptic Segmentation
Video panoptic segmentation is one of the most advanced tasks in computer vision because it combines both panoptic segmentation (semantic + instance) and temporal tracking across video frames. In simple terms, every pixel in every frame of a video must be labeled consistently. “Stuff” categories like sky, ground, or road should remain stable, while “thing” categories like cars, people, or animals must not only be segmented but also tracked through time. This creates a continuous, holistic understanding of the scene.
Why It Is Challenging
Video panoptic segmentation is difficult due to:
- Object motion: Fast-moving objects often blur or deform.
- Occlusion: Objects may disappear behind others and reappear later.
- Scale variation: An object can appear small in one frame and large in another.
- Scene dynamics: Both static (stuff) and dynamic (thing) classes need consistent labeling across time.
Maintaining pixel-accurate consistency over hundreds of frames while handling these challenges has traditionally required multiple models, which is inefficient.
Mask2Former’s Innovation
Mask2Former addresses video panoptic segmentation with a transformer-based masked attention mechanism extended into the temporal domain. Here’s how it works:
- Cross-frame attention: Queries generated for objects are not limited to one frame. They attend across frames, learning correspondences and ensuring objects are recognized consistently even with appearance changes.
- Memory integration: Features from past frames are stored and referenced when processing new frames. This helps the model “remember” identities and prevent switching labels between frames.
- Unified architecture: Instead of separate models for semantic segmentation, instance segmentation, and tracking, Mask2Former combines everything into one pipeline.
This makes the model more robust in maintaining temporal coherence and pixel-accurate segmentation across long sequences.
Benefits and Applications
- Autonomous navigation: Self-driving cars require both object recognition and scene consistency across time. Video panoptic segmentation ensures accurate understanding of roads, pedestrians, and vehicles simultaneously.
- Robotics: Robots in warehouses or outdoor environments rely on scene continuity to move and interact safely.
- AR/VR: Applications need persistent overlays across frames so that digital objects stay fixed relative to real-world environments.
- Environmental monitoring: Analyzing forest growth, glacier melting, or traffic patterns requires consistent multi-frame segmentation.
Universal Segmentation Potential
Beyond Specific Tasks
One of the strongest advantages of Mask2Former is its ability to move beyond task-specific segmentation models. Traditional segmentation systems were rigid; one network was optimized for semantic segmentation, another for instance, and yet another for panoptic or video-based tasks. This approach created silos, making deployment and training costly. Mask2Former solves this problem by merging all these tasks into one universal framework. Instead of maintaining multiple models, industries can now depend on a single transformer-based system for diverse applications.
Generalization Across Domains
Mask2Former is not restricted to academic benchmarks. Its design demonstrates strong domain generalization, meaning it can adapt to healthcare, manufacturing, agriculture, or robotics without major redesign. For example, a model trained for urban street scenes can be fine-tuned to analyze satellite images or medical scans without losing accuracy. This adaptability opens opportunities for organizations to deploy Mask2Former in multi-domain pipelines, drastically reducing development time and costs.
Flexibility for Emerging Modalities
Researchers have also highlighted the potential of Mask2Former in emerging modalities beyond 2D images. Early experiments show it can be extended to 3D point clouds, LiDAR perception, and multi-modal segmentation tasks that combine vision with text or depth sensors. This flexibility makes it future-ready, positioning Mask2Former as a backbone for multimodal AI systems. As industries move toward sensor fusion in autonomous systems, this universality becomes invaluable.
Research Extensions and Innovations
Ongoing research is pushing Mask2Former further into advanced areas. Scientists are testing its capabilities for medical imaging, where precise tumor or organ segmentation can improve diagnostics. In agriculture, drones equipped with Mask2Former can map crop health across large fields. In robotics, the model can help systems recognize and interact with objects in real time. This scalable design ensures that Mask2Former remains relevant as computer vision challenges evolve.
Future Possibilities
The true universal potential of Mask2Former lies in its ability to evolve alongside AI advancements. With generative AI integration, Mask2Former could assist in interactive scene synthesis, creating synthetic yet realistic environments. In smart cities, it could provide unified monitoring solutions that combine traffic analysis, pedestrian safety, and infrastructure health. In education, it could support immersive AR/VR environments with real-time segmentation overlays. This adaptability ensures that Mask2Former is not just a model for today, but a platform for the next era of AI-driven vision systems.
Conclusion
Mask2Former represents a revolutionary leap in computer vision by unifying semantic, instance, panoptic, video instance, and video panoptic segmentation tasks. Its masked attention mechanism provides efficiency, scalability, and accuracy, eliminating the need for separate architectures. With applications spanning healthcare, transportation, retail, surveillance, and environmental studies, Mask2Former continues to redefine universal segmentation. As research advances, its adaptability ensures it will remain a foundational model for future vision-driven technologies.