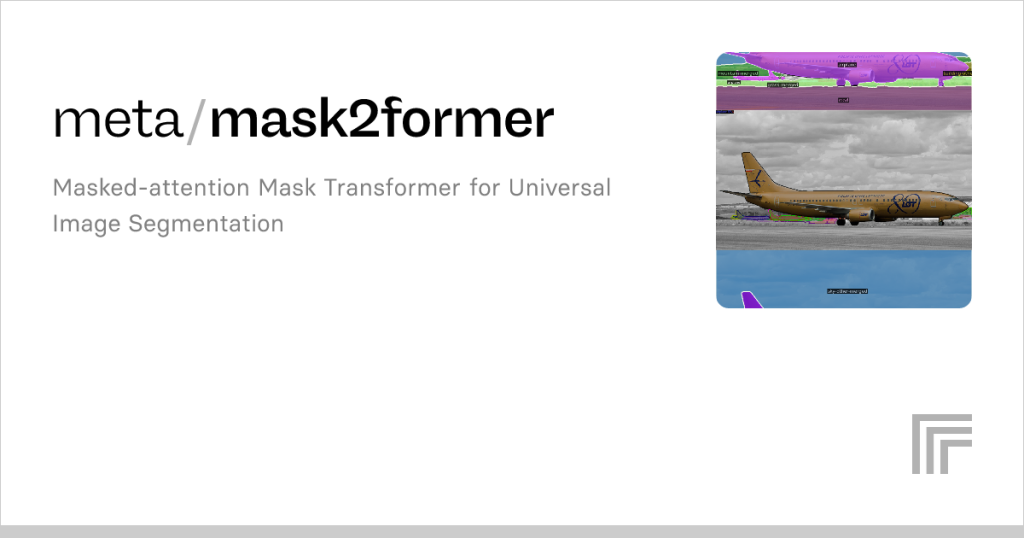

The advancement of computer vision has brought forth new algorithms capable of handling complex segmentation challenges with unmatched precision. Among these, Mask2Former has attracted strong attention for its ability to generalize across multiple segmentation tasks including semantic, instance, and panoptic segmentation. Researchers and developers want to know how accurate Mask2Former is compared to traditional models and whether it truly provides significant advantages in real-world use cases.
The model was introduced as a universal framework designed to replace task-specific architectures with a single approach adaptable to diverse datasets. This flexibility has raised questions about how well it balances accuracy, efficiency, and generalization. Professionals working in autonomous driving, healthcare, agriculture, and surveillance rely on segmentation performance, making the accuracy of Mask2Former a matter of practical importance rather than just academic interest.
To fully understand Mask2Former’s accuracy, it is necessary to explore its architecture, performance metrics, benchmarks, real-world deployment, advantages, and potential drawbacks. This article takes a detailed look at how Mask2Former performs across various conditions and tasks, providing a comprehensive evaluation for anyone considering its adoption in projects or research.
Core Design of Mask2Former
Mask2Former is built on the principle of unifying multiple segmentation tasks into a single, flexible architecture. Unlike traditional models that are designed specifically for semantic, instance, or panoptic segmentation, Mask2Former integrates all three under one framework. This design philosophy significantly reduces the need for multiple specialized models while improving consistency and accuracy across different datasets.
The Unified Framework
The unified framework of Mask2Former is designed to handle different types of segmentation tasks without changing the backbone or architecture. It uses a transformer-based approach to capture both local and global image features efficiently. This ensures that the model can understand contextual relationships across the entire image, which is especially important for complex scenes with overlapping objects or varying scales.
Masked Attention Mechanism
A key innovation of Mask2Former is the masked attention mechanism. Instead of attending to every pixel equally, the model selectively focuses on relevant regions, ignoring areas that do not contribute to accurate segmentation. This reduces noise and improves mask quality, enabling sharper boundaries and more precise object detection. The masked attention approach helps the model achieve higher accuracy compared to conventional attention methods used in older segmentation networks.
Backbone and Feature Extraction
Mask2Former typically relies on modern backbones such as ResNet or Swin Transformer to extract rich hierarchical features from images. These backbones provide multi-scale representations, which the model uses to produce precise masks. During training, the architecture optimizes for multiple segmentation losses simultaneously, allowing it to perform consistently across tasks. This backbone-feature integration is central to Mask2Former’s ability to maintain high accuracy, even in datasets with diverse image types and complex scenes.
Multi-Task Learning Advantage
By using a single architecture for multiple tasks, Mask2Former leverages shared learning across segmentation types. Knowledge gained from semantic segmentation can enhance instance segmentation performance, and vice versa. This cross-task learning reduces overfitting and allows the model to generalize better to new datasets, ultimately boosting accuracy and efficiency.
Accuracy Benchmarks Across Datasets
Cityscapes and ADE20K
When tested on Cityscapes, a dataset designed for urban scene understanding, Mask2Former achieves impressive results. It consistently ranks among the top models in mean Intersection over Union (mIoU). Similarly, in ADE20K, which contains diverse indoor and outdoor scenes, Mask2Former achieves strong generalization and maintains high-quality segmentation masks.
COCO and LVIS
For COCO instance segmentation, Mask2Former achieves accuracy comparable to or better than specialized models. On LVIS, which contains long-tail categories, it shows resilience in detecting rare classes, a task where many older models underperform. Its generalization helps provide better balance across both common and rare object categories.
Performance Summary in Benchmarks
The accuracy demonstrated by Mask2Former across datasets highlights its strength as a universal model. Reports consistently show high segmentation quality with reduced error margins. Its adaptability means it requires fewer architectural changes when switching between datasets.
- Excels in urban scene datasets such as Cityscapes
- Strong results in large-scale datasets including ADE20K
- Robust generalization to long-tail datasets like LVIS
Real-World Application Accuracy
Autonomous Driving
In autonomous vehicles, Mask2Former demonstrates superior accuracy in detecting road boundaries, vehicles, and pedestrians. This precision is critical in real-time decision-making scenarios, reducing errors in navigation systems. Many researchers now test it against LiDAR and camera fusion to enhance multi-modal perception.
Healthcare Imaging
Medical imaging tasks such as tumor segmentation or organ boundary detection rely on accuracy. Mask2Former has been applied in research environments to segment MRI and CT scans, producing consistent performance levels. While clinical deployment requires further validation, the early results suggest significant improvements over previous CNN-based models.
Agricultural and Environmental Monitoring
In agriculture, Mask2Former aids in crop health monitoring, weed detection, and land-cover segmentation. Its accuracy in identifying subtle boundaries between vegetation types provides actionable insights for precision farming. Similarly, environmental monitoring tasks like deforestation tracking or water body segmentation benefit from its detailed outputs.
Comparison With Other Segmentation Models
Mask R-CNN vs Mask2Former
Mask R-CNN was considered the gold standard for instance segmentation. However, it suffers when applied outside its intended domain. Mask2Former, with its transformer backbone, provides stronger generalization and higher accuracy across multiple segmentation categories.
- Mask R-CNN: Strong in instance segmentation, weaker in semantic tasks
- Mask2Former: Balanced across semantic, instance, and panoptic
- Greater robustness when adapting to diverse datasets
DeepLab Variants vs Mask2Former
DeepLab variants use atrous convolutions and conditional random fields for semantic segmentation. They achieve high accuracy in certain benchmarks but are less effective in panoptic or instance segmentation. Mask2Former unifies all three under one framework, often outperforming DeepLab in multi-task environments.
Swin Transformer Models vs Mask2Former
Swin Transformer-based models excel in hierarchical feature representation. While they are accurate, they usually specialize in either detection or segmentation. Mask2Former integrates similar backbones but extends functionality with its mask prediction layers, providing greater adaptability.
Strengths That Boost Accuracy
Mask2Former delivers high accuracy because of the unique strengths in its architecture and training design. Unlike older segmentation models that are tailored for one specific task, this framework was built with adaptability and scalability in mind. These strengths ensure that accuracy does not only remain high in controlled benchmarks but also transfers effectively to real-world environments where unpredictable inputs are common.
Unified Task Handling
Traditional models are often restricted to semantic or instance segmentation, forcing developers to maintain separate architectures. Mask2Former overcomes this by combining semantic, instance, and panoptic segmentation in a unified structure. This shared learning allows features extracted for one task to benefit others, which increases overall accuracy. By eliminating the need for task-specific systems, it ensures consistency across different datasets.
Transformer-Based Context Understanding
One of the core strengths boosting accuracy lies in its transformer-based backbone. Unlike CNNs that focus heavily on local features, transformers analyze global context. This helps Mask2Former understand how different objects in an image relate to one another, leading to cleaner boundaries and fewer misclassifications. By capturing long-range dependencies, the model reduces segmentation errors caused by local ambiguities.
Advantages in Efficiency and Training
Mask2Former also benefits from efficient training strategies that boost accuracy. It uses multi-task optimization, which balances loss functions across tasks, preventing overfitting on one segmentation type. Additionally, it leverages pretraining on large datasets, enhancing generalization to unseen domains.
- Avoids fragmentation between task-specific models
- Learns global and local features simultaneously
- Produces reliable and reproducible accuracy across datasets
Challenges and Limitations of Accuracy
Computational Cost
Although Mask2Former is accurate, its reliance on transformer architectures makes it computationally heavy. This can affect deployment on low-resource devices where latency and memory are critical factors.
Domain-Specific Gaps
Mask2Former performs exceptionally in general-purpose datasets but may face challenges in highly specialized domains. Accuracy could decline if the dataset contains rare patterns not well represented in the pretraining phase.
Need for Further Optimization
Despite its accuracy, ongoing research aims to optimize inference speed and resource efficiency.
- Heavy reliance on GPUs for best results
- Potential bottlenecks in real-time applications
- Scope for model compression and distillation
Conclusion
Mask2Former has established itself as one of the most accurate segmentation models available today, offering balanced performance across semantic, instance, and panoptic tasks. It demonstrates outstanding results in benchmark datasets like Cityscapes, COCO, and ADE20K while also proving effective in real-world applications ranging from autonomous driving to medical imaging. Although its computational demand remains a challenge, its ability to deliver precise, consistent, and adaptable segmentation makes it a transformative advancement in computer vision.