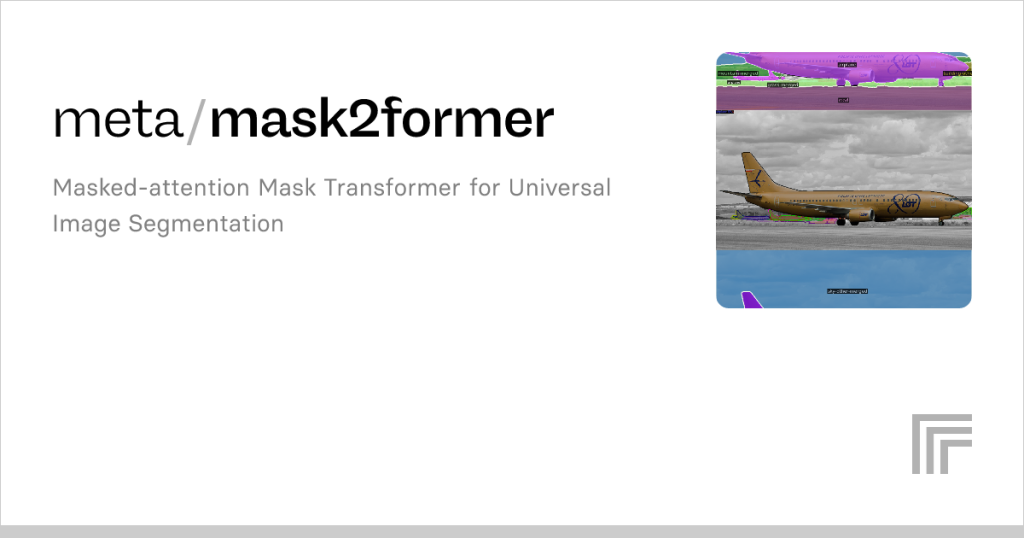
Mask2Former represents a groundbreaking advancement in computer vision, specifically designed to tackle complex image segmentation tasks with unparalleled efficiency. Developed as an evolution of the original MaskFormer model, it addresses challenges in panoptic, instance, and semantic segmentation by introducing a universal architecture. This model leverages transformer-based mechanisms to achieve state-of-the-art performance, offering a flexible and robust solution for processing images in diverse applications, from autonomous driving to medical imaging.
The core innovation of Mask2Former lies in its ability to unify different segmentation tasks under a single framework, eliminating the need for task-specific architectures. By employing a transformer decoder with masked attention, it efficiently processes image data, generating precise segmentation masks. This approach not only simplifies the model design but also enhances its adaptability, making it suitable for real-world scenarios where images vary in complexity and context.
Understanding how Mask2Former works requires delving into its technical components, such as its backbone, pixel decoder, and transformer decoder. These elements collaborate to extract features, refine them, and produce accurate segmentation outputs. This article explores the intricate workings of Mask2Former, breaking down its architecture, training process, and practical applications to provide a comprehensive understanding of its capabilities and significance in modern computer vision.
The Architecture of Mask2Former
Backbone Feature Extraction
The backbone of Mask2Former, typically a convolutional neural network (CNN) like ResNet or a vision transformer (ViT), extracts hierarchical features from input images. These features capture low-level details, such as edges, and high-level semantics, like object shapes. By processing images at multiple scales, the backbone ensures robust feature representation, enabling the model to handle diverse objects and scenes effectively. This foundational step is critical for subsequent processing stages.
Pixel Decoder for Feature Refinement
The pixel decoder in Mask2Former refines the coarse features extracted by the backbone into high-resolution representations. Using a multi-scale deformable attention mechanism, it efficiently aggregates features across different scales. This process enhances the model’s ability to capture fine-grained details, crucial for tasks like instance segmentation. The pixel decoder’s design reduces computational complexity while maintaining accuracy, making it a key component in the architecture.
Transformer Decoder with Masked Attention
The transformer decoder is the heart of Mask2Former, employing masked attention to focus on specific regions of the image. It processes a fixed number of queries, each corresponding to a potential object or region, to generate segmentation masks. This mechanism allows the model to handle multiple tasks simultaneously, ensuring precise mask predictions. The decoder’s efficiency stems from its ability to limit attention to relevant areas, optimizing performance.
How Mask2Former Handles Multiple Segmentation Tasks
Unified Framework for Segmentation
Mask2Former’s unified architecture eliminates the need for separate models for panoptic, instance, and semantic segmentation. By treating all tasks as mask classification problems, it simplifies the training and inference processes. This flexibility allows the model to adapt to various datasets and requirements. Its ability to generalize across tasks makes it a versatile tool for computer vision applications.
Task-Specific Adaptations
To support multiple segmentation tasks, Mask2Former incorporates task-specific loss functions and query formulations:
- Panoptic Segmentation: Combines semantic and instance segmentation for a comprehensive scene understanding.
- Instance Segmentation: Focuses on identifying and segmenting individual objects within an image.
- Semantic Segmentation: Assigns a class label to every pixel, ignoring instance boundaries. These adaptations ensure optimal performance across diverse scenarios. The model dynamically adjusts its output based on the task, maintaining high accuracy.
Cross-Task Knowledge Sharing
Mask2Former leverages shared representations across tasks, allowing knowledge learned from one task to benefit others. For instance, features extracted for semantic segmentation can improve instance segmentation accuracy. This cross-task synergy reduces training time and enhances generalization. By sharing weights and features, the model achieves efficiency without sacrificing performance, making it ideal for complex datasets.
The Role of Masked Attention in Mask2Former
Concept of Masked Attention
Masked attention restricts the transformer decoder’s focus to specific image regions, reducing computational overhead. Unlike traditional attention mechanisms that process the entire image, masked attention uses binary masks to prioritize relevant areas. This targeted approach improves efficiency and accuracy. It ensures that queries focus on objects or regions of interest, minimizing distractions from irrelevant parts of the image.
Implementation in Transformer Decoder
In Mask2Former, masked attention is implemented within the transformer decoder, where each query attends only to pixels within its corresponding mask. This process iteratively refines masks and class predictions. By limiting attention scope, the model reduces memory usage and speeds up processing. The implementation is optimized for high-resolution images, ensuring scalability across different applications.
Benefits for Segmentation Performance
Masked attention enhances Mask2Former’s ability to produce precise segmentation masks. By focusing on relevant regions, it minimizes errors in complex scenes with overlapping objects. This mechanism also improves robustness to occlusions and cluttered backgrounds. The result is a model that delivers consistent performance across diverse datasets, from urban scenes to medical images, with minimal computational cost.
Training Mask2Former for Optimal Performance
Dataset and Preprocessing Requirements
Training Mask2Former requires large, annotated datasets like COCO or ADE20K, which provide diverse images and segmentation labels. Preprocessing involves resizing images, normalizing pixel values, and augmenting data to improve robustness. These steps ensure the model learns to handle variations in lighting, scale, and orientation. Proper dataset preparation is crucial for achieving high generalization across real-world scenarios.
Loss Functions and Optimization
Mask2Former uses a combination of loss functions to optimize its performance:
- Cross-Entropy Loss: Ensures accurate class predictions for semantic segmentation.
- Dice Loss: Improves overlap between predicted and ground-truth masks.
- Focal Loss: Addresses class imbalance in instance segmentation. These losses are balanced to optimize both mask and class predictions. The model is typically trained using an AdamW optimizer with a learning rate scheduler to ensure convergence.
Fine-Tuning for Specific Applications
Fine-tuning Mask2Former on domain-specific datasets enhances its performance for targeted applications, such as medical imaging or autonomous driving. This process involves adjusting model weights using smaller, specialized datasets. Fine-tuning ensures the model adapts to unique challenges, like identifying rare objects or handling low-contrast images. It maximizes accuracy and reliability in real-world use cases.
Practical Applications of Mask2Former
Autonomous Driving
Mask2Former plays a vital role in autonomous driving by enabling precise segmentation of road scenes. It identifies objects like pedestrians, vehicles, and traffic signs with high accuracy. The model’s ability to handle complex urban environments ensures safe navigation. Its efficiency supports real-time processing, critical for self-driving systems. Applications include lane detection, obstacle avoidance, and scene understanding.
Medical Imaging
In medical imaging, Mask2Former excels at segmenting anatomical structures and abnormalities:
- Tumor Detection: Accurately delineates tumors in MRI or CT scans.
- Organ Segmentation: Identifies organs for surgical planning.
- Pathology Analysis: Detects cellular abnormalities in histopathology images. Its precision aids doctors in diagnosis and treatment planning. The model’s adaptability to diverse imaging modalities enhances its utility in healthcare.
Robotics and Industrial Automation
Mask2Former supports robotics by enabling object detection and scene understanding in dynamic environments. In industrial automation, it segments defective parts on assembly lines, improving quality control. Its robustness to varying lighting and object scales ensures reliable performance. Applications include robotic navigation, pick-and-place tasks, and automated inspection systems, enhancing efficiency in manufacturing.
Advantages and Limitations of Mask2Former
Key Strengths
Mask2Former’s strengths lie in its unified architecture and efficiency. It simplifies segmentation tasks by using a single model for multiple purposes, reducing development time. The masked attention mechanism enhances accuracy while minimizing computational costs. Its ability to generalize across datasets and applications makes it a powerful tool for computer vision researchers and practitioners.
Current Limitations
Despite its advancements, Mask2Former has limitations. It requires significant computational resources for training, which may be a barrier for smaller organizations. Performance can degrade on extremely small or low-quality images. Additionally, the model may struggle with rare or unseen object classes, requiring further fine-tuning to achieve optimal results in niche applications.
Future Improvements
Ongoing research aims to address Mask2Former’s limitations by optimizing its efficiency and generalization. Techniques like knowledge distillation could reduce computational demands, making it accessible to resource-constrained environments. Incorporating self-supervised learning may improve performance on unseen classes. Future iterations are expected to enhance scalability and adaptability, further solidifying Mask2Former’s role in advancing computer vision technology.
Conclusion
Mask2Former revolutionizes image segmentation by offering a unified, efficient, and versatile framework for panoptic, instance, and semantic tasks. Its innovative architecture, leveraging masked attention and transformer-based processing, delivers precise segmentation masks across diverse applications. From autonomous driving to medical imaging, Mask2Former’s impact is profound, simplifying complex workflows while maintaining high accuracy. Despite some limitations, its potential for future enhancements ensures continued relevance in computer vision, driving innovation in real-world solutions.

