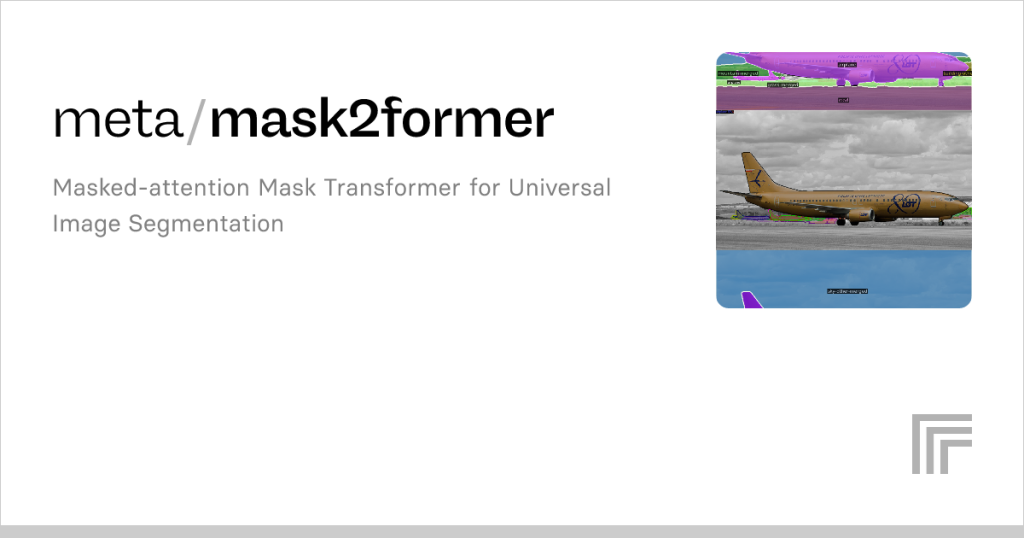

The field of computer vision has witnessed rapid advancements, with object detection and instance segmentation models driving significant progress. Two standout models, Mask2Former and DETR, have reshaped how machines interpret visual data. Mask2Former, an evolution in transformer-based architectures, promises enhanced performance in segmentation tasks. DETR, a pioneering model, introduced end-to-end object detection using transformers. Comparing these models offers insights into their strengths, limitations, and suitability for various applications.
Understanding the differences between Mask2Former and DETR requires diving into their architectures, training approaches, and performance metrics. Mask2Former builds on the transformer framework, introducing innovations that improve segmentation accuracy and efficiency. DETR, while groundbreaking, has its own unique approach to object detection, eliminating traditional components like non-maximum suppression. This article explores their technical foundations, use cases, and performance to determine which model excels in specific scenarios.
Choosing between Mask2Former and DETR depends on project requirements, computational resources, and desired outcomes. Both models leverage transformers but cater to slightly different needs in computer vision tasks. By examining their architectures, training dynamics, and real-world applications, we aim to provide a clear perspective on their capabilities. This comparison will help developers, researchers, and enthusiasts decide which model aligns best with their goals in advancing visual understanding.
Architectural Foundations
Transformer-Based Design
Both Mask2Former and DETR rely on transformer architectures, a departure from traditional convolutional neural networks. DETR uses a transformer encoder-decoder to predict object bounding boxes directly. Mask2Former extends this concept, incorporating a masked attention mechanism to handle segmentation tasks efficiently. This design allows Mask2Former to process image features with greater flexibility, enabling precise mask predictions. The transformer backbone ensures both models capture global context effectively.
Mask2Former’s Innovations
Mask2Former introduces a universal architecture for panoptic, instance, and semantic segmentation. Its masked attention module focuses on specific regions, reducing computational overhead while improving accuracy. Unlike DETR, which primarily targets object detection, Mask2Former unifies multiple segmentation tasks under one framework. This versatility makes it adaptable to diverse datasets. The model’s query-based approach refines feature extraction, enhancing performance across complex scenes.
DETR’s End-to-End Approach
DETR revolutionized object detection by eliminating post-processing steps like non-maximum suppression. Its transformer-based pipeline predicts bounding boxes and class labels in a single pass. This simplicity reduces engineering complexity but introduces challenges in handling crowded scenes. DETR’s architecture excels in scenarios with fewer objects but may struggle with fine-grained segmentation. Its design prioritizes detection over segmentation, setting it apart from Mask2Former’s broader scope.
Training Dynamics and Efficiency
Training Convergence
Training efficiency is a critical factor in model selection. DETR’s training process is notoriously slow, often requiring hundreds of epochs to converge. Mask2Former addresses this by optimizing its training pipeline, achieving faster convergence with fewer epochs. This improvement stems from its refined loss functions and query-based learning. Developers benefit from reduced training times, making Mask2Former practical for iterative experimentation.
Computational Requirements
- DETR’s Resource Intensity: DETR demands significant computational power due to its transformer-heavy architecture, especially for high-resolution images.
- Mask2Former’s Optimization: Mask2Former introduces efficiency through masked attention, lowering memory usage during training.
- Hardware Considerations: Mask2Former performs better on standard GPUs, while DETR often requires high-end hardware.
- Scalability: Mask2Former scales more effectively for large datasets, benefiting from streamlined computations.
- Practical Implications: Reduced resource demands make Mask2Former accessible to smaller research teams.
Loss Functions
Mask2Former employs a combination of binary mask loss and cross-entropy loss, tailored for segmentation tasks. This approach enhances its ability to handle overlapping objects and complex backgrounds. DETR relies on a bipartite matching loss, which aligns predictions with ground-truth boxes. While effective for detection, this loss function is less suited for pixel-level tasks. Mask2Former’s loss design contributes to its superior segmentation performance.
Performance Metrics and Benchmarks
Object Detection Accuracy
DETR set a new standard for object detection by achieving competitive results on datasets like COCO. Its end-to-end approach delivers high precision for bounding box predictions. Mask2Former, while capable of detection, prioritizes segmentation, often outperforming DETR in tasks requiring precise object boundaries. Benchmarks show Mask2Former achieving higher mean average precision (mAP) in segmentation-heavy datasets. DETR remains a strong contender for pure detection tasks.
Segmentation Capabilities
Mask2Former excels in instance and panoptic segmentation, leveraging its masked attention to produce detailed masks. It consistently achieves higher panoptic quality (PQ) scores compared to DETR. DETR, designed for detection, lacks native support for pixel-level segmentation, limiting its performance in these tasks. Mask2Former’s ability to handle multiple segmentation types makes it a versatile choice. Its performance shines in complex, densely populated scenes.
Generalization Across Datasets
Both models generalize well, but Mask2Former’s unified architecture adapts better to diverse datasets like Cityscapes and ADE20K. Its ability to handle semantic, instance, and panoptic tasks ensures robust performance across domains. DETR, while effective on COCO, struggles with datasets requiring fine-grained segmentation. Mask2Former’s flexibility makes it suitable for real-world applications where dataset variability is common. This adaptability enhances its practical utility.
Use Cases and Applications
Autonomous Driving
- Mask2Former’s Strength: Excels in panoptic segmentation, crucial for identifying lanes, pedestrians, and vehicles.
- DETR’s Role: Effective for detecting objects like traffic signs but less suited for pixel-level tasks.
- Real-Time Needs: Mask2Former’s efficiency supports faster inference, vital for autonomous systems.
- Complex Scenes: Mask2Former handles crowded urban environments better than DETR.
- Deployment: Mask2Former’s versatility makes it ideal for comprehensive scene understanding.
Medical Imaging
In medical imaging, precise segmentation of organs or anomalies is critical. Mask2Former’s ability to produce detailed masks makes it a top choice for tasks like tumor segmentation. DETR, while capable of detecting regions of interest, lacks the granularity needed for pixel-level analysis. Mask2Former’s unified approach ensures consistent performance across varied medical datasets. Its efficiency also supports faster diagnostics.
Robotics and Automation
Robotics applications require robust object detection and segmentation for navigation and manipulation. Mask2Former’s ability to handle both tasks simultaneously makes it ideal for robotic vision systems. DETR’s detection-focused design suits simpler tasks like object tracking but struggles with detailed scene parsing. Mask2Former’s faster inference and adaptability enhance its suitability for real-time robotic applications. Its performance supports complex automation workflows.
Limitations and Challenges
Scalability Issues
- DETR’s Bottlenecks: Slow convergence and high memory usage limit scalability for large datasets.
- Mask2Former’s Improvements: Optimized attention mechanisms reduce computational demands.
- Large-Scale Datasets: Mask2Former handles high-resolution images more efficiently.
- Training Time: DETR’s lengthy training process hinders rapid deployment.
- Resource Constraints: Mask2Former’s efficiency makes it viable for resource-limited settings.
Handling Complex Scenes
DETR struggles with crowded scenes due to its reliance on bipartite matching, which can miss overlapping objects. Mask2Former’s masked attention mechanism excels in such scenarios, accurately segmenting dense environments. This makes Mask2Former preferable for applications like urban surveillance. DETR’s simpler architecture may lead to missed detections in cluttered images. Mask2Former’s robust design mitigates these challenges effectively.
Model Complexity
DETR’s end-to-end simplicity reduces engineering overhead but limits its flexibility for segmentation tasks. Mask2Former, while more complex, offers a unified framework that balances versatility and performance. Its architecture requires more expertise to fine-tune, posing a learning curve for developers. DETR’s straightforward design is easier to implement but less adaptable. Mask2Former’s complexity is justified by its superior results.
Future Prospects and Developments
Mask2Former’s Evolution
Mask2Former’s universal architecture positions it as a foundation for future segmentation models. Ongoing research aims to further optimize its attention mechanisms, reducing computational costs. Its adaptability to new tasks, like video segmentation, shows promise for dynamic applications. Integration with real-time systems is a key focus for its development. Mask2Former’s trajectory suggests it will remain a leader in segmentation.
DETR’s Continued Relevance
DETR’s simplicity ensures its relevance in detection-focused applications. Improvements like Deformable DETR address its scalability issues, enhancing performance. Future iterations may incorporate segmentation capabilities, narrowing the gap with Mask2Former. Its lightweight design appeals to resource-constrained environments. DETR’s evolution will likely focus on balancing efficiency and versatility.
Industry Adoption
Both models are gaining traction in industries like autonomous driving and healthcare. Mask2Former’s versatility makes it a preferred choice for complex tasks, while DETR’s simplicity suits rapid prototyping. Advances in hardware and training techniques will further democratize their use. Collaborative frameworks combining their strengths could emerge. Their adoption will drive innovation in computer vision applications.
Conclusion
Mask2Former and DETR represent significant milestones in computer vision, each excelling in distinct areas. Mask2Former’s unified architecture and efficiency make it ideal for segmentation-heavy tasks, while DETR’s simplicity suits detection-focused applications. Choosing between them depends on project needs, computational resources, and dataset complexity. Mask2Former’s versatility often gives it an edge, but DETR remains valuable for specific use cases. Both models continue to shape the future of visual understanding, offering powerful tools for innovation.