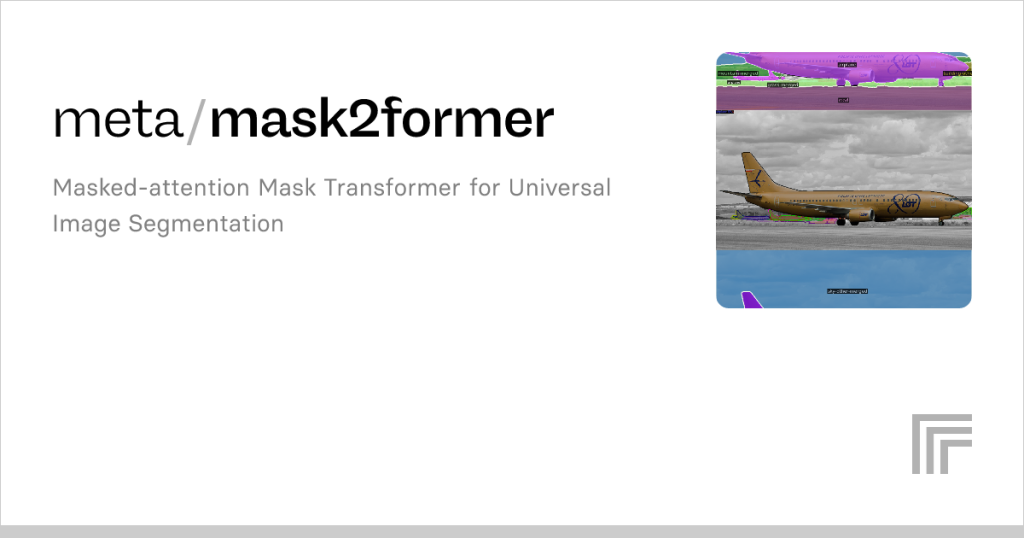

Image segmentation, a cornerstone of computer vision, empowers machines to understand images by dividing them into meaningful regions. Mask2Former and U-Net, two powerful models, have emerged as leading solutions in this domain, each offering unique strengths for tasks like medical imaging, autonomous driving, and object detection. While U-Net has long been a go-to architecture for pixel-level segmentation, Mask2Former introduces advanced capabilities for both instance and semantic segmentation, sparking interest among researchers and developers. Understanding their differences is key to choosing the right tool for specific applications.
Both models excel in segmenting images but cater to slightly different needs. U-Net, introduced in 2015, revolutionized medical image segmentation with its encoder-decoder structure, enabling precise pixel-wise predictions. Mask2Former, a more recent innovation, leverages transformer-based architecture to handle a broader range of segmentation tasks, including panoptic, instance, and semantic segmentation. By comparing their architectures, performance, and use cases, we can uncover which model suits particular project requirements and how they push the boundaries of computer vision.
This article dives deep into the comparison between Mask2Former and U-Net, exploring their technical foundations, strengths, and limitations. From architectural design to real-world applications, we’ll break down how these models perform across various scenarios. Whether you’re a researcher, developer, or enthusiast in computer vision, this guide provides a clear, comprehensive look at how Mask2Former and U-Net stack up, helping you make informed decisions for your next segmentation project.
Architectural Design Differences
U-Net’s Encoder-Decoder Structure
U-Net’s architecture, built for biomedical image segmentation, features a symmetric encoder-decoder design. The encoder extracts features by reducing spatial dimensions through convolutional layers, while the decoder upsamples these features to reconstruct the segmentation map. Skip connections between the encoder and decoder preserve spatial details, making U-Net highly effective for pixel-level tasks. This structure ensures efficient feature propagation, particularly for high-resolution images.
Mask2Former’s Transformer-Based Approach
Mask2Former relies on a transformer-based architecture, a significant departure from U-Net’s convolutional roots. It uses a backbone network to extract features, followed by a pixel decoder and transformer decoder to generate segmentation masks. This design leverages attention mechanisms to capture global context, enabling Mask2Former to handle complex scenes with multiple objects. Its flexibility supports various segmentation types, unlike U-Net’s focus on semantic segmentation.
Impact on Model Flexibility
U-Net’s architecture is tailored for pixel-wise segmentation, excelling in scenarios with uniform object classes. However, it struggles with tasks requiring instance-level separation, such as distinguishing overlapping objects. Mask2Former’s transformer-based design offers greater flexibility, accommodating semantic, instance, and panoptic segmentation within a unified framework. This adaptability makes Mask2Former a versatile choice for diverse computer vision challenges, while U-Net remains more specialized.
Performance Across Segmentation Tasks
Semantic Segmentation Capabilities
- U-Net: Excels in semantic segmentation, assigning each pixel a class label, particularly in medical imaging. Its skip connections ensure precise boundary delineation, ideal for tasks like tumor detection.
- Mask2Former: Also performs well in semantic segmentation, leveraging transformers to capture global context. It often outperforms U-Net in complex scenes with varied object classes due to its attention mechanisms.
- Key Difference: Mask2Former’s global feature understanding gives it an edge in diverse datasets, while U-Net shines in high-precision, domain-specific tasks.
- Performance Metrics: Mask2Former typically achieves higher mean Intersection over Union (mIoU) on datasets like COCO, while U-Net remains competitive in medical datasets like ISIC.
- Use Case Fit: U-Net suits specialized tasks; Mask2Former handles broader, multi-class scenarios.
Instance Segmentation Performance
- U-Net: Limited in instance segmentation, as it lacks mechanisms to distinguish individual objects of the same class. Modifications like Mask R-CNN integrations are needed for instance-level tasks.
- Mask2Former: Designed for instance segmentation, it generates unique masks for each object instance using transformer-based queries. This makes it ideal for crowded scenes with overlapping objects.
- Key Difference: Mask2Former’s ability to separate instances natively gives it a clear advantage over U-Net, which requires additional frameworks.
- Performance Metrics: Mask2Former achieves superior Average Precision (AP) scores on instance segmentation benchmarks like COCO.
- Use Case Fit: Mask2Former is the go-to for instance segmentation in autonomous driving or robotics.
Panoptic Segmentation Support
- U-Net: Not designed for panoptic segmentation, which combines semantic and instance segmentation. Adapting U-Net for this task requires significant modifications and additional modules.
- Mask2Former: Natively supports panoptic segmentation, unifying semantic and instance predictions in a single model. Its transformer decoder efficiently handles both “stuff” and “things” classes.
- Key Difference: Mask2Former’s unified framework simplifies panoptic tasks, while U-Net struggles with this complexity.
- Performance Metrics: Mask2Former consistently outperforms on panoptic quality (PQ) metrics across datasets like Cityscapes.
- Use Case Fit: Mask2Former excels in applications requiring holistic scene understanding, such as urban planning or augmented reality.
Training and Computational Requirements
Hardware Demands
U-Net’s convolutional architecture is relatively lightweight, making it accessible for training on modest hardware, such as single GPUs. Its simplicity allows for faster training times, particularly on smaller datasets. However, scaling U-Net to larger, more complex datasets can increase computational costs. Researchers with limited resources often favor U-Net for its efficiency. It remains a practical choice for medical imaging labs with constrained hardware.
Training Data Needs
Mask2Former’s transformer-based design requires substantial computational resources and larger datasets to achieve optimal performance. Its reliance on attention mechanisms demands high memory bandwidth, often necessitating multiple high-end GPUs or TPUs. While this enables Mask2Former to handle diverse datasets, it can be a barrier for smaller teams. U-Net, by contrast, performs well with smaller, domain-specific datasets, making it more accessible for targeted applications.
Time to Convergence
U-Net typically converges faster during training due to its simpler architecture and lower parameter count. This efficiency suits projects with tight timelines or limited data. Mask2Former, with its complex transformer layers, requires longer training periods to fine-tune its attention mechanisms. However, its ability to generalize across tasks can justify the extended training time for applications requiring versatility, such as autonomous vehicle perception systems.
Use Cases and Applications
Medical Imaging Applications
- U-Net: Widely used in medical imaging for tasks like organ segmentation, tumor detection, and cell counting. Its precision in pixel-level predictions makes it a staple in radiology and pathology.
- Mask2Former: Less common in medical imaging but shows promise in complex cases, such as segmenting overlapping cells or tissues with varied textures.
- Key Difference: U-Net’s specialized design dominates medical applications, while Mask2Former’s flexibility suits experimental or multi-class medical tasks.
- Example: U-Net excels in brain MRI segmentation; Mask2Former could enhance multi-organ segmentation in CT scans.
- Adoption: U-Net is the standard in medical research; Mask2Former is gaining traction for advanced cases.
Autonomous Driving Scenarios
- U-Net: Applied in lane detection and road segmentation but struggles with instance-level tasks like identifying individual vehicles or pedestrians.
- Mask2Former: Excels in autonomous driving, handling instance and panoptic segmentation for comprehensive scene understanding, including vehicles, pedestrians, and traffic signs.
- Key Difference: Mask2Former’s ability to process complex, dynamic scenes gives it an edge in autonomous driving.
- Example: Mask2Former can segment and track multiple objects in real-time traffic scenarios, while U-Net focuses on static road features.
- Adoption: Mask2Former is preferred for full-scene analysis in self-driving systems.
General Computer Vision Tasks
- U-Net: Best suited for tasks requiring high precision in controlled environments, such as satellite image segmentation or material defect detection.
- Mask2Former: Shines in general computer vision tasks like object detection in natural images or video frame analysis, thanks to its versatility.
- Key Difference: Mask2Former’s transformer-based approach handles diverse, real-world scenarios better than U-Net’s specialized design.
- Example: Mask2Former excels in segmenting crowded urban scenes; U-Net is ideal for structured, single-class segmentation.
- Adoption: Mask2Former is favored in industries requiring robust, multi-task segmentation.
Strengths and Limitations
U-Net’s Key Advantages
- Simplicity: U-Net’s straightforward architecture is easy to implement and modify, making it accessible for beginners and experts alike.
- Efficiency: Requires less computational power, enabling training on standard hardware with faster iteration cycles.
- Precision: Skip connections ensure high accuracy in pixel-level tasks, particularly in medical imaging.
- Community Support: Extensive adoption in research provides a wealth of pre-trained models and tutorials.
- Domain-Specific Strength: Tailored for biomedical applications, U-Net delivers reliable results in structured datasets.
Mask2Former’s Key Advantages
- Versatility: Handles semantic, instance, and panoptic segmentation within a single framework, reducing the need for multiple models.
- Global Context: Transformer-based attention captures relationships across distant image regions, improving performance in complex scenes.
- Scalability: Adapts well to large, diverse datasets, making it suitable for real-world applications.
- State-of-the-Art Results: Achieves top performance on benchmarks like COCO and Cityscapes for various segmentation tasks.
- Future-Proof Design: Its transformer architecture aligns with modern trends in deep learning, ensuring long-term relevance.
Limitations to Consider
- U-Net: Struggles with instance segmentation and complex scenes requiring global context, limiting its use in dynamic environments.
- Mask2Former: High computational demands and longer training times can be mosey for smaller teams or resource-constrained projects.
- U-Net: Less flexible for non-semantic tasks, often requiring additional frameworks for instance or panoptic segmentation.
- Mask2Former: Complex architecture demands expertise in transformer-based models, posing a learning curve for some users.
- Trade-Offs: U-Net’s simplicity sacrifices versatility; Mask2Former’s versatility comes at the cost of resource intensity.
Future Potential and Developments
U-Net’s Evolution
U-Net continues to evolve through variants like U-Net++ and Attention U-Net, which enhance feature extraction and focus on relevant regions. These adaptations improve performance in medical imaging and other pixel-wise tasks. Researchers are exploring lightweight versions for edge devices, expanding U-Net’s reach. Its established presence ensures ongoing community-driven improvements. Future iterations may incorporate hybrid architectures to address instance segmentation limitations.
Mask2Former’s Advancements
Mask2Former is poised for growth as transformer-based models advance. Improvements in efficiency, such as optimized attention mechanisms, could reduce computational demands. Integration with real-time processing pipelines may enhance its use in dynamic applications like robotics. Ongoing research aims to make Mask2Former more accessible to smaller teams. Its unified framework positions it as a leader in next-generation segmentation tasks.
Emerging Trends in Segmentation
Both models will benefit from trends like self-supervised learning and multimodal integration. U-Net may adopt attention mechanisms to improve context awareness, while Mask2Former could leverage pre-trained vision transformers for better generalization. Advances in hardware, like specialized AI chips, will mitigate computational barriers. Hybrid models combining U-Net’s efficiency with Mask2Former’s flexibility may emerge. These developments promise enhanced accuracy and broader application scopes.
Conclusion
Mask2Former and U-Net offer distinct strengths in image segmentation, with U-Net excelling in precise, domain-specific tasks like medical imaging and Mask2Former shining in versatile, complex scenarios like autonomous driving. Their architectural differences—U-Net’s convolutional efficiency versus Mask2Former’s transformer-based flexibility—shape their ideal use cases. Choosing between them depends on project needs, resources, and segmentation goals. As computer vision evolves, both models will adapt, driving innovation in segmentation accuracy and application diversity.