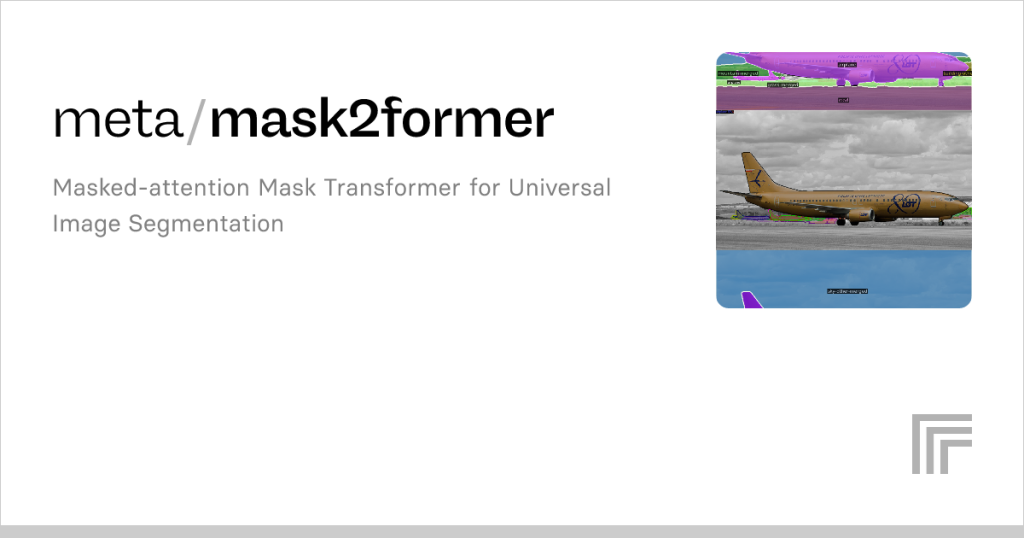

Mask2Former, an advanced framework for image segmentation, has sparked significant interest in the computer vision community. Its ability to handle multiple segmentation tasks, such as semantic, instance, and panoptic segmentation, within a single architecture makes it a versatile tool. Researchers and developers are drawn to its transformer-based design, which delivers state-of-the-art performance across diverse datasets. However, a critical question remains: can Mask2Former operate efficiently enough for real-time applications? Understanding its potential requires examining its architecture, computational demands, and practical use cases.
Real-time applications, such as autonomous driving, robotics, and augmented reality, demand low latency and high accuracy. Mask2Former’s unified approach to segmentation offers advantages over traditional models, but its computational complexity poses challenges. Balancing performance with speed is essential for deploying such models in time-sensitive environments. Factors like hardware capabilities, optimization techniques, and specific task requirements play a pivotal role in determining whether Mask2Former can meet real-time demands.
This article explores Mask2Former’s suitability for real-time applications by analyzing its architecture, performance metrics, and optimization strategies. It delves into the model’s strengths, limitations, and potential adaptations for dynamic scenarios. By examining hardware dependencies, software optimizations, and real-world use cases, we aim to provide a comprehensive understanding of whether Mask2Former can achieve the speed and efficiency required for real-time deployment in cutting-edge technologies.
Mask2Former’s Architecture
Core Components of Mask2Former
Mask2Former builds on transformer-based architectures, leveraging a backbone network like ResNet or Swin Transformer to extract features. It uses a pixel decoder to refine these features and a transformer decoder to generate mask predictions. This modular design enables it to handle multiple segmentation tasks. However, the transformer’s attention mechanisms and high-resolution feature processing increase computational overhead, impacting real-time feasibility.
How It Differs from Previous Models
Unlike its predecessor, Mask R-CNN, Mask2Former unifies semantic, instance, and panoptic segmentation into one framework. It employs masked attention to focus on relevant image regions, improving accuracy but adding complexity. Compared to models like YOLO, which prioritize speed, Mask2Former emphasizes precision. This trade-off makes real-time implementation challenging without significant optimization or hardware acceleration.
Computational Complexity Analysis
Mask2Former’s computational demands stem from its transformer layers and high-resolution feature maps. The model requires substantial memory and processing power, particularly for large images. Complexity scales with input resolution and the number of predicted masks. For real-time applications, this necessitates efficient hardware or model pruning to reduce latency while maintaining acceptable accuracy levels.
Performance Metrics for Real-Time Applications
Latency and Throughput Requirements
Real-time applications typically require processing speeds of at least 30 frames per second (FPS). Mask2Former’s latency depends on input size and hardware. On high-end GPUs, it achieves moderate FPS, but performance drops on resource-constrained devices. Key metrics include:
- Inference time per image
- Frames per second on target hardware
- Memory usage during processing
- Scalability with increasing image resolution
- Trade-offs between accuracy and speed
Accuracy vs. Speed Trade-Off
Mask2Former delivers high accuracy, often surpassing 50% AP (Average Precision) on datasets like COCO. However, achieving this precision requires heavy computation, slowing inference. Real-time systems may tolerate slight accuracy losses for faster processing. Techniques like quantization or reducing mask queries can lower latency but may degrade segmentation quality, requiring careful calibration for specific tasks.
Benchmarking Against Other Models
Compared to lightweight models like MobileNet-based segmentors, Mask2Former is slower but more accurate. Benchmarks on COCO show it achieves top-tier AP scores, but inference times often exceed 100ms per image on standard GPUs. Faster models like YOLOv8 prioritize speed (under 30ms per image) but sacrifice segmentation detail. Mask2Former’s performance makes it better suited for applications prioritizing precision over speed.
Hardware Requirements for Real-Time Deployment
GPU and TPU Capabilities
High-end GPUs, such as NVIDIA’s A100 or RTX 4090, can handle Mask2Former’s demands, achieving near-real-time speeds for smaller images. TPUs, optimized for matrix operations, further reduce latency. However, these devices are expensive and power-hungry, limiting accessibility. Real-time deployment requires balancing hardware cost with performance, often necessitating cloud-based or edge-optimized solutions.
Edge Device Limitations
Deploying Mask2Former on edge devices like Jetson Nano or mobile processors is challenging due to limited compute power. These devices struggle with the model’s memory and processing requirements, resulting in high latency. Optimizations like model compression or specialized hardware (e.g., Coral TPU) are necessary to approach real-time performance, but they may compromise accuracy or functionality.
Scalability Across Hardware
Mask2Former’s performance scales with hardware capabilities. High-resolution inputs demand more powerful GPUs or TPUs, while low-resolution tasks may run on mid-tier devices. Distributed computing or multi-GPU setups can enhance throughput for large-scale applications. However, scaling introduces complexity in synchronization and resource management, impacting deployment feasibility in dynamic environments.
Optimization Techniques for Real-Time Use
Model Pruning and Quantization
Pruning reduces Mask2Former’s parameters by eliminating redundant connections, lowering computational load. Quantization converts floating-point weights to lower-bit representations, speeding up inference. These techniques can achieve:
- Reduced model size (e.g., 50% smaller footprint)
- Lower inference time (up to 2x faster)
- Minimal accuracy loss with careful tuning
- Improved compatibility with edge devices
- Enhanced energy efficiency for mobile applications
Efficient Inference Pipelines
Optimizing inference pipelines involves batch processing, parallelization, and caching intermediate results. Frameworks like ONNX or TensorRT accelerate Mask2Former by optimizing operations for specific hardware. Streamlining data preprocessing and postprocessing also reduces latency. These pipelines are critical for applications like autonomous driving, where consistent low-latency performance is non-negotiable.
Knowledge Distillation for Speed
Knowledge distillation trains a smaller “student” model to mimic Mask2Former’s outputs, retaining much of its accuracy with less complexity. The distilled model runs faster, making it suitable for real-time tasks. This approach requires careful design to balance performance and speed, but it offers a promising path for deploying Mask2Former in resource-constrained environments.
Real-World Applications and Feasibility
Autonomous Driving Scenarios
In autonomous vehicles, real-time segmentation is critical for obstacle detection and scene understanding. Mask2Former’s high accuracy makes it ideal for complex urban environments, but its latency (often >100ms) is a bottleneck. Optimizations like quantization or dedicated hardware can reduce delays, enabling:
- Precise object and lane segmentation
- Robust performance in diverse conditions
- Integration with LIDAR and radar data
- Scalability for multi-camera systems
- Enhanced safety through accurate predictions
Robotics and Industrial Automation
Robotics applications, such as warehouse automation or robotic arms, require fast and precise segmentation. Mask2Former excels in identifying objects but struggles with real-time constraints on edge devices. Optimized versions or cloud-based processing can bridge this gap, enabling tasks like object grasping or defect detection in manufacturing with improved efficiency.
Augmented Reality and Gaming
Augmented reality (AR) demands real-time segmentation for seamless overlays. Mask2Former’s detailed mask predictions enhance AR experiences, but its computational demands limit performance on mobile devices. Lightweight adaptations or GPU-accelerated platforms can make it viable, supporting applications like interactive gaming or virtual try-ons with high-quality visual effects.
Challenges and Future Directions
Current Limitations in Real-Time Use
Mask2Former’s primary limitation is its high computational cost, driven by transformer layers and large feature maps. Real-time performance is achievable only with high-end hardware or significant optimization. Latency issues on edge devices and energy consumption also pose challenges. Addressing these requires advancements in model efficiency and hardware compatibility to meet real-time demands.
Emerging Optimization Trends
Future improvements may leverage neural architecture search to design faster variants of Mask2Former. Techniques like dynamic inference, which adjusts model complexity based on input, show promise. Hardware advancements, such as next-generation edge TPUs or specialized AI chips, could further enable real-time deployment, making Mask2Former more accessible for diverse applications.
Potential for Hybrid Models
Hybrid models combining Mask2Former’s accuracy with lightweight architectures like YOLO could offer a balanced solution. By integrating fast feature extractors with Mask2Former’s transformer-based mask prediction, these models could achieve real-time performance without sacrificing quality. Research into such hybrids is ongoing, promising a future where complex segmentation tasks are feasible in dynamic settings.
Conclusion
Mask2Former’s advanced segmentation capabilities make it a powerful tool, but its real-time applicability hinges on optimization and hardware. While high-end GPUs enable near-real-time performance, edge devices require model pruning, quantization, or distillation to meet latency demands. Applications like autonomous driving and AR benefit from its precision, yet computational challenges persist. Future advancements in hardware and hybrid models could unlock Mask2Former’s full potential, enabling seamless real-time deployment across diverse, dynamic environments.