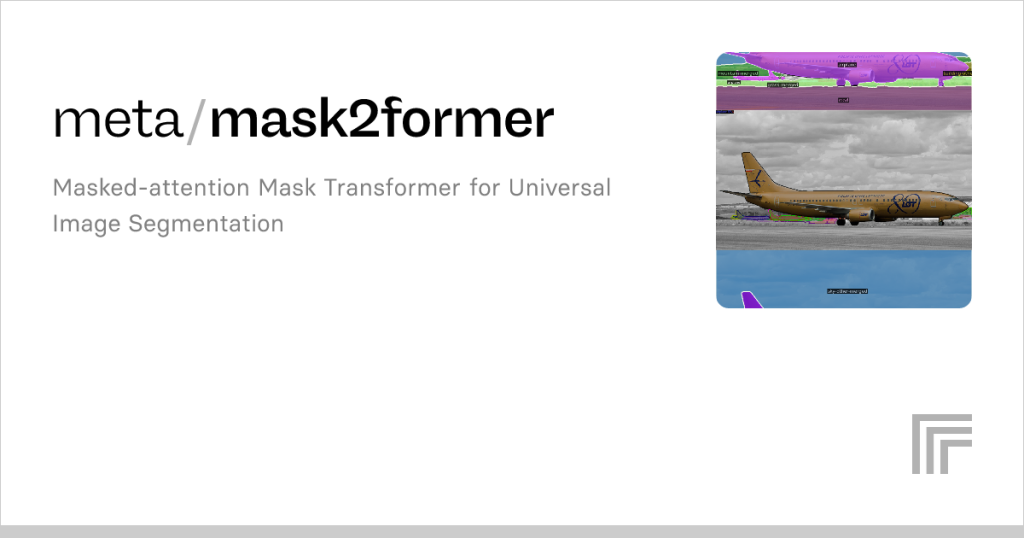

Mask2Former, a cutting-edge model in the realm of computer vision, has garnered significant attention for its remarkable performance in image segmentation tasks. Developed as an advanced framework for universal image segmentation, it excels in instance, semantic, and panoptic segmentation, leveraging a transformer-based architecture to achieve state-of-the-art results. Its ability to handle diverse segmentation challenges with high accuracy has made it a go-to solution for researchers and practitioners. However, as video-based applications continue to grow in importance—spanning autonomous driving, surveillance, and video editing—a critical question emerges: can Mask2Former effectively handle video tasks? This article explores Mask2Former’s capabilities, its potential for video processing, and the challenges and opportunities it presents in this dynamic domain.
The evolution of computer vision models has shifted focus toward video tasks, where temporal consistency and real-time processing are paramount. Unlike static images, videos introduce complexities such as motion blur, occlusion, and frame-to-frame coherence, demanding models that can track objects and segment scenes across time. Mask2Former’s architecture, built on transformer principles, offers a robust foundation for addressing these challenges, but its original design targets static images. Understanding whether it can adapt to video tasks requires examining its core mechanisms, training paradigms, and potential extensions to handle temporal data effectively.
This exploration aims to provide a comprehensive analysis of Mask2Former’s applicability to video tasks. By delving into its architectural strengths, limitations, and the modifications needed for video processing, we uncover how this model can be leveraged or adapted for real-world video applications. From tracking objects across frames to maintaining segmentation consistency, we evaluate its performance and highlight practical approaches to extend its capabilities. Let’s dive into the details of Mask2Former’s potential in the video domain and what it means for the future of computer vision.
Understanding Mask2Former’s Core Architecture
Transformer-Based Design
Mask2Former’s architecture relies on a transformer backbone, which processes input images through self-attention mechanisms to capture global context. This enables precise segmentation by modeling relationships between pixels across the entire image. The model’s mask classification approach assigns binary masks to objects, enhancing its flexibility for various segmentation tasks. Its design prioritizes efficiency and accuracy, making it a strong candidate for adaptation to video tasks.
Query-Based Segmentation
The model employs a query-based mechanism, where learnable queries interact with image features to generate segmentation masks. This approach reduces computational overhead compared to traditional per-pixel classification methods. By focusing on object-level predictions, Mask2Former achieves high-quality results in instance and semantic segmentation. However, its static nature raises questions about handling temporal dynamics in videos, where queries must account for motion and continuity.
Handling Diverse Segmentation Tasks
Mask2Former’s versatility lies in its ability to unify instance, semantic, and panoptic segmentation under a single framework. It leverages a shared architecture to process different tasks, minimizing the need for task-specific modifications. This unified approach suggests potential for video tasks, where similar principles could apply to temporal segmentation. Yet, adapting this framework to maintain consistency across frames remains a critical challenge for video applications.
Challenges of Video Tasks in Computer Vision
Temporal Consistency
Videos require models to maintain object identity and segmentation accuracy across frames. Temporal consistency ensures that objects tracked over time retain coherent boundaries and labels. Mask2Former, designed for static images, lacks inherent mechanisms to enforce this consistency. Without modifications, it may struggle with frame-to-frame variations caused by motion or lighting changes, leading to flickering or misidentification in video segmentation.
Motion and Occlusion Handling
Motion blur and occlusion are common in videos, complicating segmentation tasks. Objects moving rapidly or partially obscured challenge the model’s ability to delineate boundaries accurately. Mask2Former’s pixel-level precision in images may not directly translate to videos, where motion dynamics require robust tracking. Addressing these issues demands strategies like optical flow integration or temporal feature aggregation to enhance performance.
Real-Time Processing Demands
Video tasks often require real-time processing for applications like autonomous driving or live surveillance. Mask2Former’s computational complexity, while optimized for images, may hinder its ability to process high-frame-rate videos efficiently. Achieving real-time performance necessitates lightweight adaptations or hardware acceleration. Balancing speed and accuracy becomes a pivotal challenge when extending Mask2Former to video scenarios.
Extending Mask2Former for Video Segmentation
Incorporating Temporal Modules
To handle video tasks, Mask2Former can integrate temporal modules like recurrent neural networks (RNNs) or 3D convolutions. These modules capture temporal dependencies by linking features across frames. For instance, adding a temporal transformer layer could enable the model to track objects over time. Such modifications would allow Mask2Former to maintain segmentation consistency while leveraging its existing strengths in spatial analysis.
Leveraging Optical Flow
Optical flow, which estimates pixel motion between frames, can enhance Mask2Former’s video capabilities. By incorporating flow-based features, the model can predict object movement and adjust segmentation masks accordingly. This approach helps address motion blur and occlusion, improving tracking accuracy. Key benefits include:
- Enhanced object tracking across frames
- Reduced errors from motion-induced distortions
- Improved handling of dynamic scenes
- Better adaptation to varying frame rates
- Increased robustness to partial occlusions
Fine-Tuning on Video Datasets
Adapting Mask2Former for videos requires fine-tuning on video-specific datasets like YouTube-VIS or DAVIS. These datasets provide annotated frames to train models for temporal segmentation. Fine-tuning enables the model to learn motion patterns and maintain object consistency. This process involves updating the transformer queries to account for temporal features, ensuring Mask2Former aligns with the unique demands of video tasks.
Current Applications of Mask2Former in Video Tasks
Video Instance Segmentation
Mask2Former has shown promise in video instance segmentation when adapted with temporal extensions. By combining its query-based approach with temporal feature aggregation, it can track and segment objects across frames. Applications include video editing, where precise object masks are needed for effects like background replacement. Early experiments demonstrate that modified versions of Mask2Former achieve competitive results on benchmarks like YouTube-VIS.
Video Semantic Segmentation
Semantic segmentation in videos requires labeling every pixel across frames consistently. Mask2Former’s ability to handle semantic tasks in images suggests potential for video applications. By incorporating temporal consistency constraints, it can maintain label coherence in dynamic scenes. Use cases include:
- Autonomous driving for road and obstacle detection
- Surveillance for identifying objects in real time
- Augmented reality for scene understanding
- Robotics for environment mapping
- Video analytics for crowd monitoring
Panoptic Video Segmentation
Panoptic segmentation, combining instance and semantic tasks, is more complex in videos due to temporal dynamics. Mask2Former’s unified framework makes it a strong candidate for this task. With adaptations like temporal attention mechanisms, it can segment both “things” (objects) and “stuff” (backgrounds) across frames. This capability is vital for applications requiring holistic scene understanding, such as autonomous navigation.
Limitations of Mask2Former in Video Processing
Lack of Native Temporal Modeling
Mask2Former’s design focuses on static images, lacking native support for temporal modeling. Without modifications, it processes each frame independently, leading to inconsistent segmentation in videos. This limitation causes issues like object flickering or loss of identity across frames. Addressing this requires significant architectural changes, such as integrating temporal transformers or memory modules to retain frame-to-frame information.
Computational Complexity
Video tasks demand processing multiple frames, increasing computational load. Mask2Former’s transformer-based architecture, while efficient for images, may struggle with high-resolution or high-frame-rate videos. This complexity can lead to latency, making it unsuitable for real-time applications without optimization. Techniques like model pruning or quantization could mitigate this, but they may compromise accuracy. Key challenges include:
- High memory usage for long sequences
- Increased inference time for complex scenes
- Scalability issues with high-frame-rate videos
- Resource demands for real-time processing
- Trade-offs between speed and segmentation quality
Limited Video-Specific Training
Mask2Former’s pre-training on image datasets like COCO limits its exposure to video-specific challenges. Motion patterns, occlusions, and temporal variations are not adequately addressed in its default configuration. Fine-tuning on video datasets is essential but may not fully bridge the gap without architectural enhancements. This limitation underscores the need for video-specific pre-training or hybrid training strategies.
Future Directions for Mask2Former in Video Tasks
Hybrid Architectures
Combining Mask2Former with video-specific models like Video Swin Transformer could enhance its capabilities. Hybrid architectures leverage the strengths of both spatial and temporal processing. For example, integrating Mask2Former’s query-based segmentation with temporal attention mechanisms could enable robust video segmentation. This approach promises improved performance in dynamic environments, paving the way for broader adoption in video tasks.
Self-Supervised Learning for Videos
Self-supervised learning on large-scale video datasets could improve Mask2Former’s temporal understanding. By training on unannotated videos, the model can learn motion patterns and temporal coherence without extensive labeled data. This approach reduces dependency on costly annotations and enhances adaptability to diverse video scenarios. Future research could focus on self-supervised strategies tailored to Mask2Former’s architecture.
Real-Time Optimization
Optimizing Mask2Former for real-time video processing is crucial for practical applications. Techniques like knowledge distillation or efficient transformer variants could reduce computational overhead. Additionally, leveraging hardware accelerators like GPUs or TPUs can enhance inference speed. These advancements would make Mask2Former viable for time-sensitive tasks, such as autonomous driving or live video analytics, without sacrificing segmentation quality.
Conclusion
Mask2Former’s prowess in image segmentation highlights its potential for video tasks, but its static design requires adaptations to handle temporal dynamics. By incorporating temporal modules, leveraging optical flow, and fine-tuning on video datasets, it can address challenges like motion blur and occlusion. While limitations such as computational complexity and lack of native temporal modeling persist, hybrid architectures and self-supervised learning offer promising paths forward. With these advancements, Mask2Former could become a powerful tool for video segmentation, driving innovation in computer vision applications.