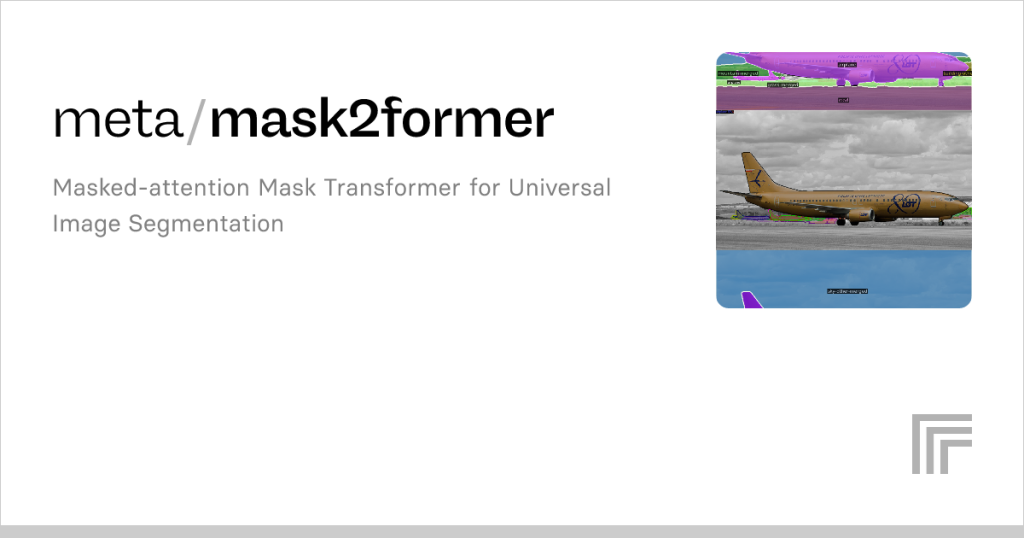

Image segmentation, a pivotal technique in computer vision, involves dividing an image into distinct regions, each representing a specific object or area with semantic meaning. This process is critical for applications ranging from autonomous vehicles detecting pedestrians and road signs to medical imaging systems identifying tumors or anatomical structures. As the demand for precise, scalable, and efficient segmentation models intensifies, Mask2Former has emerged as a transformative solution. Built on a transformer-based architecture, it promises unparalleled accuracy and versatility, addressing the evolving needs of researchers and industry professionals tackling complex visual data.
What distinguishes Mask2Former is its innovative approach to unifying diverse segmentation tasks—instance, semantic, and panoptic—within a single, cohesive framework. Unlike traditional models that require separate architectures for each task, Mask2Former streamlines the process, reducing complexity and enhancing flexibility. Rooted in the success of transformer models like DETR, it leverages advanced mechanisms such as mask attention to optimize performance across varied datasets, making it a compelling choice for real-world applications where precision and adaptability are paramount.
This article delves into Mask2Former’s architecture, performance metrics, strengths, limitations, and practical applications to evaluate its effectiveness for image segmentation. By exploring its technical foundations and real-world impact, we aim to provide a comprehensive understanding of its capabilities. Whether you’re a data scientist, AI researcher, or industry practitioner, this analysis will help you assess whether Mask2Former is the right tool for your segmentation challenges. Let’s explore its potential to redefine computer vision and uncover any constraints that may influence its adoption.
Understanding Mask2Former’s Architecture
Core Transformer-Based Design
Mask2Former’s architecture is built on a transformer-based framework, utilizing a backbone such as Swin or ResNet to extract rich, hierarchical features from input images. These features are processed by a transformer decoder, which generates mask predictions in an end-to-end manner. By eliminating the need for manual post-processing steps, the model enhances computational efficiency and simplifies workflows. This design is particularly effective for handling complex segmentation tasks, making it a robust choice for diverse applications requiring high precision.
Mask Attention Mechanism
A standout feature of Mask2Former is its mask attention mechanism, which focuses computational resources on specific image regions during prediction. Unlike traditional pixel-wise attention, which can be computationally expensive, mask attention prioritizes object boundaries and relevant areas, reducing resource demands. This approach significantly improves segmentation accuracy, especially for small, intricate, or overlapping objects. By optimizing attention allocation, Mask2Former achieves superior performance in challenging scenarios, setting a new standard for transformer-based models.
Unified Segmentation Framework
Mask2Former’s ability to unify instance, semantic, and panoptic segmentation under a single architecture is a game-changer. By treating all segmentation tasks as mask classification problems, it simplifies both training and inference processes. This unified approach eliminates the need for multiple specialized models, saving time and resources. Researchers benefit from a flexible framework that adapts seamlessly to various datasets and task requirements, making it an attractive option for projects demanding versatility and scalability.
Performance Across Segmentation Tasks
Instance Segmentation Excellence
Mask2Former excels in instance segmentation, where it identifies and delineates individual objects within an image. On benchmarks like COCO, it achieves impressive average precision (AP) scores, often outperforming predecessors such as Mask R-CNN. Its ability to handle complex scenes with multiple, overlapping objects is a key strength. The model’s robustness ensures reliable performance in cluttered environments, making it ideal for applications requiring precise object detection and delineation, such as robotics or augmented reality.
Semantic Segmentation Capabilities
In semantic segmentation, Mask2Former assigns a class label to every pixel, delivering high performance on datasets like ADE20K with strong mean Intersection over Union (mIoU) scores. Its strengths include:
- Precise boundary detection for accurate pixel classification
- Effective handling of class imbalances in diverse datasets
- Efficient processing of high-resolution images with minimal latency
- Strong generalization to unseen scenes and categories
- Reduced need for extensive task-specific hyperparameter tuning These capabilities make Mask2Former a reliable choice for pixel-level classification tasks across industries, from urban planning to environmental monitoring.
Panoptic Segmentation Strengths
Panoptic segmentation, which combines instance and semantic tasks, is where Mask2Former truly shines. It delivers state-of-the-art results on COCO panoptic benchmarks, effectively balancing “things” (countable objects like cars) and “stuff” (amorphous regions like roads). Its unified framework ensures consistent performance across both aspects, providing a holistic understanding of complex scenes. This makes it a top choice for applications requiring comprehensive scene parsing, such as autonomous navigation or surveillance systems.
Computational Efficiency and Scalability
Resource Requirements
Mask2Former’s transformer-based design requires significant computational resources, particularly during training. High-end GPUs or TPUs are often necessary to process large datasets efficiently. However, its optimized mask attention mechanism reduces inference-time demands, making it feasible for deployment on less powerful hardware. This balance between training complexity and inference efficiency suits projects with access to robust computational infrastructure, ensuring practical applicability in resource-rich environments.
Scalability Across Datasets
The model scales effectively across datasets of varying sizes, from small academic datasets to large-scale industrial ones. Its architecture accommodates different image resolutions and complexities, making it adaptable to diverse use cases. Pre-trained models enable transfer learning, further enhancing scalability. This flexibility allows Mask2Former to support a wide range of applications, from experimental research to large-scale production deployments in industries like agriculture or geospatial analysis.
Training and Inference Speed
Training Mask2Former can be resource-intensive, often requiring numerous epochs to achieve convergence on large datasets. However, inference speed is competitive, particularly when paired with optimized backbones like ResNet-50. For real-time applications, lighter backbones provide a practical trade-off between speed and accuracy. This efficiency during deployment makes Mask2Former suitable for time-sensitive tasks, such as real-time object detection in autonomous systems or live video analysis.
Strengths of Mask2Former for Image Segmentation
Versatility Across Tasks
Mask2Former’s ability to handle instance, semantic, and panoptic segmentation within a single framework is a major advantage. This versatility reduces development time and eliminates the need for multiple models, streamlining workflows. It’s particularly valuable for projects requiring diverse segmentation outputs, such as autonomous driving systems needing both object and scene-level understanding. Researchers and developers benefit from a unified approach that simplifies experimentation and deployment.
High Accuracy and Robustness
Mask2Former delivers exceptional accuracy across segmentation benchmarks, making it a reliable choice for mission-critical applications. Its robustness to occlusions, cluttered scenes, and varying lighting conditions enhances performance in real-world scenarios. Key strengths include:
- Superior detection of small or intricate objects
- Consistent results across diverse environmental conditions
- Effective handling of overlapping instances in crowded scenes
- Strong generalization to new, unseen datasets
- Minimal reliance on complex post-processing pipelines These qualities ensure dependable performance in challenging segmentation tasks.
Adaptability to New Domains
The model’s pre-trained weights and transfer learning capabilities make it highly adaptable to new domains. Fine-tuning on specialized datasets, such as medical imaging or satellite imagery, yields strong results with minimal effort. This adaptability is crucial for industries with unique segmentation needs, such as healthcare, agriculture, or urban planning. Mask2Former’s flexibility enables rapid customization, making it a valuable tool for domain-specific applications.
Limitations and Challenges
High Computational Cost
Despite its efficiency during inference, Mask2Former’s training phase demands substantial computational resources. High memory and processing requirements can be a barrier for smaller teams or projects with limited hardware access. Scaling to very large datasets may further exacerbate these challenges. Careful resource planning and access to powerful hardware are essential to fully leverage Mask2Former’s capabilities, particularly for large-scale training.
Complexity in Implementation
Implementing Mask2Former requires a deep understanding of transformer architectures and segmentation tasks. Fine-tuning hyperparameters and optimizing the model for specific use cases can be daunting, especially for those new to deep learning. While pre-trained weights simplify the process, customization may still pose challenges. This complexity can extend development timelines, requiring experienced teams to achieve optimal results.
Dependence on Quality Data
Like most deep learning models, Mask2Former’s performance hinges on high-quality, well-annotated datasets. Noisy or poorly labeled data can significantly degrade accuracy, particularly for niche applications with limited labeled data. Acquiring sufficient, high-quality annotations for specialized domains, such as rare medical conditions or unique environmental scenarios, can be costly and time-consuming. Robust data pipelines are critical to maximizing the model’s potential.
Practical Applications and Use Cases
Autonomous Vehicles
Mask2Former is a powerful tool for autonomous driving, segmenting complex road scenes into objects like vehicles, pedestrians, and traffic signs. Its ability to handle dynamic, cluttered environments ensures reliable performance in real-world conditions. For instance, it accurately distinguishes overlapping objects in busy urban settings, enabling safer navigation. Its precision and robustness make it a cornerstone for developing advanced driver-assistance systems and fully autonomous vehicles.
Medical Imaging
In healthcare, Mask2Former excels at segmenting medical images, such as MRI, CT, or ultrasound scans. It identifies critical structures like organs, tumors, or blood vessels with high accuracy, supporting diagnostics and treatment planning. Its adaptability to small, specialized datasets is particularly valuable for rare conditions. By providing precise segmentations, Mask2Former enhances clinical workflows, enabling faster and more accurate medical interventions.
Industrial and Remote Sensing
Mask2Former supports industrial applications by segmenting satellite or drone imagery for tasks like crop monitoring, infrastructure inspection, or environmental analysis. Its robustness to varying resolutions and conditions ensures reliable results. Key benefits include:
- Accurate classification of land cover types
- Detection of small defects in manufacturing processes
- Monitoring of environmental changes like deforestation
- Support for urban planning and development
- Scalability to large-scale, high-resolution imagery These capabilities drive innovation across sectors, from agriculture to geospatial intelligence.
Conclusion
Mask2Former represents a significant leap forward in image segmentation, offering a unified, transformer-based framework that excels in instance, semantic, and panoptic tasks. Its high accuracy, robustness, and adaptability make it a top choice for applications like autonomous driving, medical imaging, and remote sensing. While challenges like high computational costs and implementation complexity exist, its strengths make it a compelling solution for well-resourced teams. For those seeking a versatile, cutting-edge segmentation model, Mask2Former pushes the boundaries of computer vision, delivering exceptional value and performance across diverse domains.