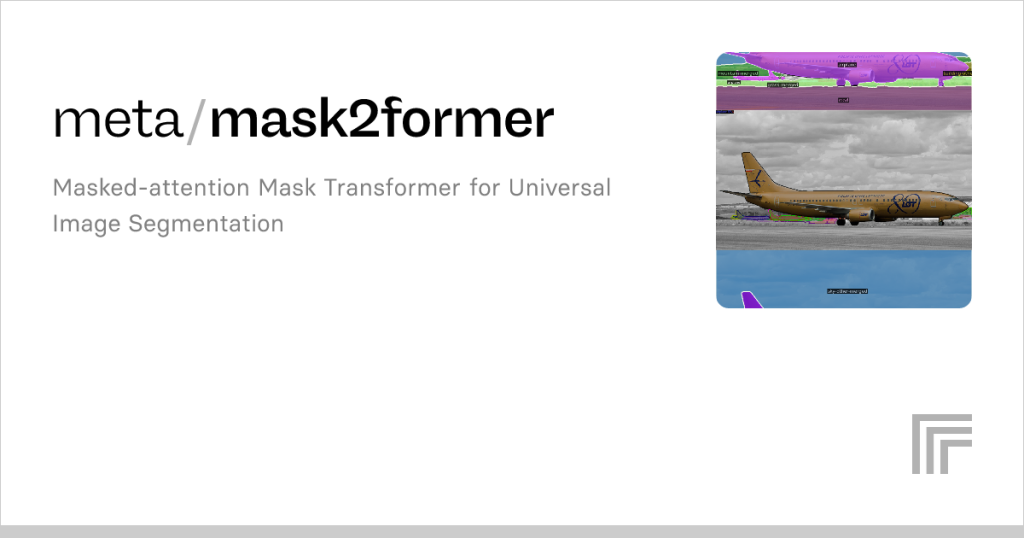

Mask2Former, a cutting-edge transformer-based model, revolutionizes image segmentation by excelling in semantic, instance, and panoptic tasks. Its unified architecture, leveraging transformer decoders, delivers precise mask predictions and class assignments, making it a top choice for computer vision applications. Selecting optimal datasets for training or fine-tuning Mask2Former is crucial to unlocking its full potential. The right dataset ensures the model learns robust features, adapts to diverse scenarios, and performs reliably in real-world settings.
The quality, diversity, and relevance of datasets significantly influence Mask2Former’s generalization capabilities. High-quality annotations provide accurate ground truth, enabling the model to capture intricate details in images. Diverse datasets, spanning various environments, objects, and conditions, enhance the model’s adaptability to complex scenes. Whether your focus is autonomous driving, medical imaging, or indoor robotics, choosing datasets tailored to your domain is essential for maximizing Mask2Former’s accuracy and computational efficiency.
This article dives into the best datasets for training and fine-tuning Mask2Former, analyzing their characteristics, annotation types, and suitability for specific tasks. From general-purpose benchmarks like COCO to specialized datasets like Cityscapes and ADE20K, we explore options that cater to diverse applications. By understanding each dataset’s strengths, limitations, and annotation details, you can make informed decisions to optimize Mask2Former’s performance, ensuring it meets the demands of your project with precision and reliability.
COCO (Common Objects in Context) Dataset
Overview of COCO
The COCO dataset, a cornerstone in computer vision, is widely adopted for training segmentation models like Mask2Former. It comprises over 200,000 images across 80 object categories, capturing a wide range of scenes from everyday life to complex environments. Its extensive annotations support instance, semantic, and panoptic segmentation, making it a versatile choice. The dataset’s large scale and diversity enable Mask2Former to learn robust, generalizable features, critical for its transformer-based architecture.
Annotation Types and Quality
COCO offers pixel-level annotations for instance segmentation, including bounding boxes and precise masks, alongside panoptic annotations that combine “thing” (e.g., objects like cars) and “stuff” (e.g., backgrounds like sky) classes. Its human-verified annotations ensure high accuracy, minimizing errors during training. Standardized evaluation metrics, such as mean Average Precision (mAP) for instance segmentation and Panoptic Quality (PQ) for panoptic tasks, provide reliable benchmarks. This makes COCO an excellent foundation for optimizing Mask2Former’s mask prediction and classification capabilities.
Best Use Cases for Mask2Former
COCO is ideal for general-purpose segmentation tasks, particularly in applications like robotics, augmented reality, or object detection in consumer devices. Its broad category coverage, from animals to household items, ensures Mask2Former can segment diverse objects in cluttered scenes. Fine-tuning on COCO enhances the model’s ability to handle complex, real-world environments, making it a go-to dataset for foundational training before specializing in niche domains like medical imaging or urban navigation.
Cityscapes Dataset
Introduction to Cityscapes
Cityscapes is a specialized dataset tailored for urban scene understanding, particularly in autonomous driving. It includes 5,000 finely annotated high-resolution images and 20,000 coarsely annotated images from 50 cities, focusing on street-level scenes. The dataset’s detailed annotations and diverse urban environments make it a top choice for training Mask2Former on complex outdoor settings. Its focus on dynamic, densely populated scenes aligns perfectly with the model’s ability to generate precise masks in challenging conditions.
Key Features and Annotations
- Semantic Segmentation: Offers pixel-level labels for 30 classes, including vehicles, pedestrians, roads, and buildings, enabling detailed scene parsing.
- Instance Segmentation: Provides instance-level annotations for eight key classes, such as cars, cyclists, and buses, critical for distinguishing individual objects.
- High-Resolution Images: Images at 2048×1024 pixels capture fine-grained details, ideal for Mask2Former’s high-precision mask generation.
- Diverse Conditions: Includes scenes from various seasons, weather, and lighting conditions, enhancing model robustness.
- Evaluation Metrics: Uses mean Intersection over Union (mIoU) for semantic segmentation and Average Precision (AP) for instance tasks, aligning with Mask2Former’s evaluation needs.
Ideal Applications for Mask2Former
Cityscapes is perfect for training Mask2Former for autonomous vehicle systems, traffic monitoring, and urban planning applications. Its detailed annotations enable the model to differentiate closely spaced objects, such as pedestrians and vehicles, in crowded urban scenes. Fine-tuning on Cityscapes improves Mask2Former’s performance in real-world driving scenarios, ensuring accurate segmentation under challenging conditions like rain, fog, or low-light environments, making it invaluable for safety-critical systems.
ADE20K Dataset
What Is ADE20K?
ADE20K is a comprehensive dataset designed for scene parsing, containing 20,210 training images and 2,000 validation images across 150 semantic categories. It covers both indoor and outdoor scenes, including objects like furniture and scene elements like walls and sky. Its rich annotations and diverse scenes make it a versatile choice for Mask2Former. The dataset’s focus on contextual understanding supports the model’s unified architecture for semantic and panoptic segmentation.
Annotation Details
ADE20K provides pixel-level annotations for both “things” (e.g., chairs, people) and “stuff” (e.g., floors, trees), enabling robust training for semantic and panoptic tasks. Its meticulously curated annotations cover a wide range of scenes, from domestic interiors to natural landscapes. The dataset’s emphasis on scene parsing helps Mask2Former learn contextual relationships between objects, improving segmentation accuracy. Its standardized mIoU metric ensures consistent performance evaluation, making it a reliable choice for training.
Why Use ADE20K with Mask2Former?
ADE20K is ideal for training Mask2Former for applications like indoor robotics, augmented reality, and advanced scene understanding. Its extensive category coverage enables the model to generalize across diverse environments, from homes to public spaces. Fine-tuning on ADE20K enhances Mask2Former’s ability to segment complex scenes with overlapping objects, making it suitable for tasks requiring detailed contextual awareness, such as smart home systems or virtual environment rendering.
Mapillary Vistas Dataset
Overview of Mapillary Vistas
Mapillary Vistas is a large-scale street-level dataset with 25,000 high-resolution images sourced from global urban and rural environments. It supports semantic and instance segmentation with 66 object categories, including fine-grained classes like road markings, traffic signs, and streetlights. Its global diversity, high-quality annotations, and challenging conditions make it an excellent choice for training Mask2Former on real-world, dynamic scenes, particularly in urban settings.
Annotation and Data Characteristics
- Rich Semantic Labels: Includes 66 classes covering vehicles, pedestrians, infrastructure, and environmental elements, ideal for urban segmentation tasks.
- Instance Annotations: Provides instance-level labels for key objects, supporting Mask2Former’s instance segmentation capabilities.
- Global Diversity: Images from various continents ensure robustness across different cultural and environmental contexts.
- High-Resolution Images: Resolutions up to 4000×6000 pixels enable precise mask predictions, leveraging Mask2Former’s transformer architecture.
- Challenging Conditions: Includes night, fog, rain, and other adverse conditions, enhancing the model’s adaptability to real-world scenarios.
Applications for Mask2Former
Mapillary Vistas is well-suited for training Mask2Former for autonomous driving, urban mapping, and smart city applications. Its diverse, high-resolution images help the model handle complex urban scenes with multiple overlapping objects. Fine-tuning on this dataset improves Mask2Former’s robustness to varying lighting, weather, and cultural differences, making it ideal for real-world deployment in navigation systems, traffic analysis, and infrastructure monitoring.
Pascal VOC Dataset
Introduction to Pascal VOC
Pascal VOC (Visual Object Classes) is a classic computer vision dataset with 11,530 images across 20 object categories, including animals, vehicles, and household items. Though smaller than modern datasets, its high-quality annotations for semantic and instance segmentation remain valuable for Mask2Former. Its simplicity and focus on common objects make it an excellent starting point for training, benchmarking, or rapid prototyping in resource-constrained settings.
Key Features and Annotations
- Semantic Segmentation: Provides pixel-level labels for 20 classes, covering objects like cars, dogs, and furniture, enabling detailed scene analysis.
- Instance Segmentation: Includes bounding boxes and masks for precise object delineation, supporting Mask2Former’s instance tasks.
- Moderate Scale: Smaller dataset size allows faster experimentation and iteration, ideal for initial model training.
- High-Quality Annotations: Human-verified labels ensure accuracy, reducing noise during training.
- Evaluation Metrics: Uses mIoU for semantic segmentation and AP for instance segmentation, aligning with Mask2Former’s performance metrics.
Best Scenarios for Mask2Former
Pascal VOC is suitable for training Mask2Former on smaller-scale projects or as a baseline before scaling to larger datasets like COCO or Mapillary Vistas. It’s ideal for applications like object recognition in consumer electronics, basic scene understanding, or educational research. Fine-tuning on Pascal VOC enables Mask2Former to achieve quick, reliable results in controlled environments, making it a practical choice for projects with limited computational resources.
LVIS Dataset
What Is LVIS?
LVIS (Large Vocabulary Instance Segmentation) is a large-scale dataset with 100,000 images and over 1,200 object categories, emphasizing long-tail distributions. Its extensive category coverage, from common objects like chairs to rare ones like “ocarina” or “segway,” makes it a powerful choice for training Mask2Former on diverse, real-world scenarios. The dataset’s focus on rare objects helps the model generalize to less common classes, enhancing its versatility.
Annotation Types and Scale
LVIS provides detailed instance segmentation annotations, including masks and bounding boxes, for a vast range of categories. Its large-scale, high-quality annotations support robust training for Mask2Former’s transformer-based architecture. The dataset’s evaluation metrics, such as AP for instance segmentation, ensure precise performance assessment. Its long-tail focus challenges the model to learn nuanced features, improving its ability to handle rare or underrepresented objects in complex scenes.
Why Choose LVIS for Mask2Former?
LVIS is ideal for training Mask2Former for applications requiring fine-grained object recognition, such as e-commerce, robotics, or inventory management. Its extensive category coverage ensures the model can segment both common and rare objects, improving generalization across diverse scenarios. Fine-tuning on LVIS enhances Mask2Former’s ability to handle cluttered, real-world scenes with multiple object types, making it suitable for complex tasks like autonomous exploration or product cataloging.
Conclusion
Choosing the right dataset for Mask2Former hinges on your project’s specific requirements, whether it’s autonomous driving, indoor robotics, or fine-grained object recognition. Datasets like COCO, Cityscapes, ADE20K, Mapillary Vistas, Pascal VOC, and LVIS offer unique strengths, from broad category coverage to specialized urban annotations. By aligning the dataset’s characteristics with your application’s needs, you can optimize Mask2Former’s performance, ensuring accurate, robust, and efficient segmentation across diverse, real-world scenarios.